

VII-C. Résultat sur un extranet▲
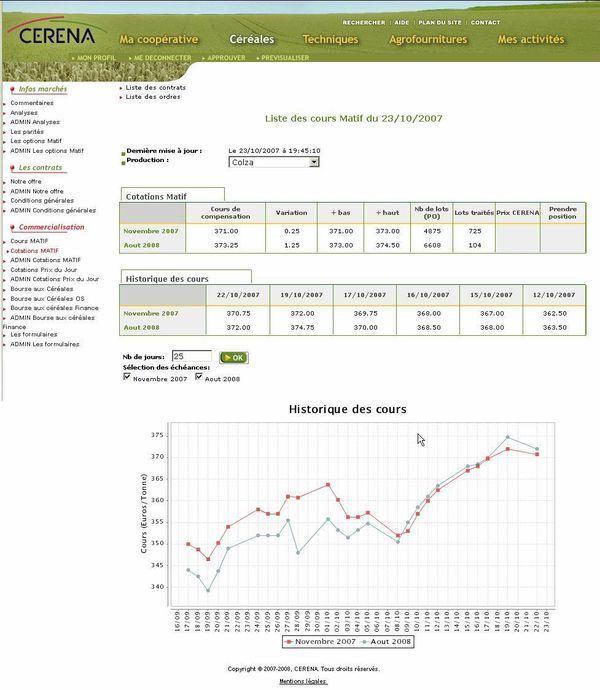
Le résultat du traitement d'intégration de données permet de visualiser quotidiennement à partir de 19h45 les cours de clôture du MATIF sur chacun des extranets.
Les données sont présentées de façon tabulaire et graphiques :
VII-D. Feedback sur l'utilisation de « Pentaho Data Integration »▲
Dans ce contexte métier très précis, voici les éléments que l'on peut retirer de l'utilisation d'un ETL Open Source :
- Phase de Conception/Développement :
L'utilisation de Pentaho Data Integration est très simple et intuitive, il n'y a pratiquement aucun code à écrire pour la conception et la définition des traitements d'intégration.
Il y a donc des gains conséquents en terme de développement, malheureusement on ne peut pas s'affranchir de l'analyse (!)
La documentation, les « samples » fournis avec l'outil et le site de Pentaho Data Integration (kettle.pentaho.org) permettent bien souvent de trouver la solution à un point de blocage.
Les fonctions de prévisualisation de l'ETL permettent de tester efficacement les traitements lors de la phase de développement.
- Phase d'installation :
Il suffit juste d'installer Pentaho Data Integration sur le serveur cible (décompression d'un zip, installation de java 1.5 si besoin), puis ensuite de planifier les traitements batch (via crontab sous Linux).
Le déploiement des jobs peut se faire par recopie du « repository » de DEV sur le serveur de PROD (remontée du dump de la bdd du repository kettle)
- Phase de production :
Chaque jour, les mails de notification permettent d'être informés du bon déroulement des traitements.
A ce jour, aucun « plantage » n'a été constaté depuis la mise en production effectuée le 23 Mai 2007.
- Maintenance :
La maintenance évolutive ou corrective est grandement simplifée du fait de la vision graphique des traitements et du découpage de ceux-ci en briques élémentaires.
Si jamais un jour il faut aller chercher les données via webservice, il suffira de remplacer l'étape « parsing XML » par un «webservice call »
- Coûts de licences :
Aucun