



I. Introduction▲
Conscients que l'une des plus grandes richesses d'une entreprise est son information, mais noyés sous de nombreuses données, éparses, déstructurées et hétérogènes, les dirigeants sont face à une problématique de taille : comment analyser ces informations, dans des temps raisonnables ? Celles-ci concernent-elles toutes les mêmes périodes ? Ces décideurs ont besoin qu'on leur expose les faits importants, base de leurs décisions.
C'est ce à quoi l'informatique décisionnelle (aussi nommée DSS pour Decision Support System ou encore BI pour Business Intelligence) est destinée. Elle prend une place en constante croissance dans les systèmes d'information (SI) depuis son apparition, dans les années quatre-vingt-dix.
Elle permet une sélection des informations opérationnelles pertinentes pour l'entreprise. Celles-ci sont ensuite normalisées pour alimenter un entrepôt de données. De ce concept est née la notion de modélisation dimensionnelle. Cette dernière est fondamentale pour répondre aux exigences de rapidité et de facilité d'analyse. Elle permet, en outre, de rendre les données d'un entrepôt cohérentes, lisibles, intelligibles et faciles d'accès.
L'informatique décisionnelle doit produire des indicateurs et des rapports à l'attention des analystes. Elle doit également proposer des outils de navigation, d'interrogation et de visualisation de l'entrepôt.
II. Le modèle multidimensionnel▲
Le modèle multidimensionnel est la combinaison de tables de dimensions et de faits. Le fait est le sujet de l'analyse. Il est formé de mesures, généralement numériques, renseignées de manière continue. Ces mesures permettent de résumer un grand nombre d'enregistrements des données sources en quelques-uns. Le fait est analysé selon des perspectives, nommées dimensions. Chacune contient une structure hiérarchique ; la dimension « temps », par exemple, pourrait être divisée en années, trimestres, mois, semaines, jours...
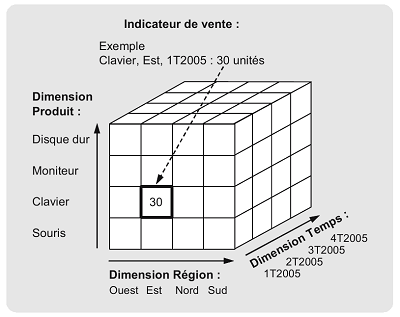
De cette hiérarchie découle le niveau de granularité de l'entrepôt, et donc, les niveaux d'agrégations. La figure ci-dessus montre le cube permettant l'analyse de l'« indicateur de vente » selon trois dimensions : produit, temps (divisé en trimestres), et région.
III. Architecture d'un système décisionnel▲
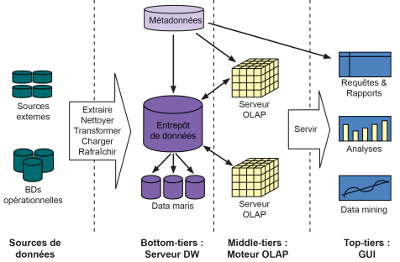
Cette section propose de parcourir les différents éléments nécessaires à la mise en place d'une solution d'aide à la décision, depuis l'extraction des données jusqu'à leur restitution sous forme agrégée, synthétisée et normalisée.
III-A. Sources de données▲
Afin d'alimenter les entrepôts, les informations doivent être identifiées et extraites de leurs emplacements originels. Il s'agit majoritairement de données internes à l'entreprise, mais diffuses, car stockées dans les bases de données de production des différents services (legacy systems). Ce peut être aussi des sources externes, récupérées via des services distants, des web services, par exemple. Ce sont des données complexes : plusieurs technologies (types de fichiers, encodages, liens d'accès aux systèmes de gestion de bases de données SGBD), environnements (systèmes d'exploitation, matériels) et principes de sécurité pour les atteindre (mécanismes réseaux, authentifications) entrent en jeu pour les acquérir.
III-B. Outils d'extraction, transformation et chargement▲
Plus connus sous le terme anglo-saxon Extract Transform Load (ETL), ces outils sont fondamentaux pour la construction des entrepôts de données. Ils extraient les données des systèmes hétérogènes sources, les normalisent et les rendent cohérentes entre elles, pour qu'elles puissent être utilisées ensemble. Les données sont fournies dans un format permettant leur stockage immédiat dans les entrepôts, et ultérieurement exploitables, sans recalculs par les décideurs et les analystes.
En accord avec le résultat à obtenir, et une fois les données importantes localisées dans les systèmes sources, l'outil doit les extraire, selon une fréquence déterminée (planification).
Elles sont alors stockées temporairement (staging). Cette étape et le type de fichier choisi pour ce stockage (fichiers plats, XML, tables relationnelles, etc.) sont décisifs car ils permettent de filtrer et fédérer les données afin de les rendre homogènes :
- Le filtrage sert à identifier les données aberrantes ou problématiques, notamment les données manquantes ;
- Le dédoublonnage est nécessaire lorsque plusieurs sources de données partagent des données communes ;
- Le formatage est crucial, notamment dans le cas de données codifiées (par exemple, des abréviations difficilement convertibles), ou de dates qui doivent être décomposées en un ensemble de champs (année, mois, jour, heure, minute, etc.), contenant chacun une information pertinente ;
- La dénormalisation est inévitable si la source est une base de données relationnelle, qui utilise généralement la troisième forme normale (3FN), interdisant toute redondance. À noter que le formatage et la dénormalisation peuvent être contradictoires car dans le cas de fichiers sources dont les informations sont déjà dénormalisées, il est alors préférable de les normaliser à nouveau ;
- La synchronisation garantit la cohérence des agrégats de l'entrepôt ;
- L'agrégation est une collection d'opérations possibles à effectuer sur les données. Les plus courantes sont la somme, la moyenne, le comptage, la somme cumulée, le minimum, le maximum. Ces opérations sont à considérer compte tenu du niveau de granularité de l'entrepôt.
Ces tâches conditionnent la qualité des données du système décisionnel. À ce titre, cette étape apparaît comme « la plus importante et la plus complexe à effectuer lors de l'implantation d'un entrepôt de données ».
III-C. Entrepôt de données▲
L'entrepôt de données « est une base de données architecturée pour des requêtes et des analyses, plutôt que pour le traitement transactionnel des données », et les résultats de ces requêtes doivent être obtenus rapidement.
L'entrepôt est organisé sur le modèle multidimensionnel évoqué précédemment. Il y a néanmoins deux types de stockage :
- L'entrepôt (data warehouse), qui concentre toutes les données ;
- Le marché de données (data mart) focalise sur une partie du métier, comme les relations clients, par exemple.
Yvan Bédard a précisé que « l'entrepôt [...] est prévu pour l'entreprise dans son ensemble alors que le marché de données est sectoriel (il peut être un sous-ensemble exact ou modifié de l'entrepôt de données) ».
III-D. Traitement analytique en ligne OLAP▲
En 1993, Edgar Frank Codd introduit le terme On-Line Analytical Processing (OLAP) qui « désigne une catégorie d'applications et de technologies permettant de collecter, stocker, traiter et restituer des données multidimensionnelles à des fins d'analyses ».
Il a aussi introduit 12 « règles de base » permettant de qualifier l'OLAP :
- Transparence : l'utilisateur doit pouvoir accéder à la base, sans se préoccuper de l'emplacement du serveur ;
- Accessibilité : les données doivent toutes être accessibles, sans ambiguïté ;
- Manipulation des données : la navigation doit pouvoir s'effectuer intuitivement via des interfaces ergonomiques ;
- Souplesse d'affichage et flexibilité : le serveur doit permettre souplesse pour l'édition et réutilisation des rapports générés ;
- Multidimensionnalité : il s'agit de la nature même d'OLAP ;
- Client-serveur : architecture du système ;
- Multi-utilisateur : l'accès et les recherches simultanés de la base doivent être possibles ;
- Stabilité : les performances sont indépendantes du nombre de dimensions, ce nombre et le niveau d'agrégation doivent pouvoir être modifiés sans impact sur les temps de réponse ;
- Gestion complète : le serveur supporte la représentation d'informations manquantes ;
- Croisement des dimensions : le système permet d'effectuer des opérations entre et dans les dimensions ;
- Dimensionnalité générique : toutes les dimensions d'un hypercube doivent être accessibles de manière générique, elles sont, de plus, indépendantes ;
- Analyse sans limite : le nombre de dimensions et de niveaux d'agrégation permet des analyses complexes.
Entre entrepôt et OLAP, il n'y a qu'un pas. En effet, l'entrepôt est le lieu de stockage physique des données, tandis que l'OLAP est l'outil permettant leur analyse multidimensionnelle.
Celle-ci est l'objet d'une requête particulière, émise par l'utilisateur, a contrario du forage (data mining) qui vise la recherche de corrélations entre les données dans l'intégralité de l'entrepôt.
Afin de rendre l'analyse la moins contraignante et la plus souple possible, l'OLAP propose des opérateurs. Il s'agit de mécanismes servant à naviguer dans les hiérarchies et les dimensions. Les opérateurs permettent de :
- Tailler (slicing, scoping) : autorise l'extraction d'une tranche, d'un bloc d'informations. Il s'agit d'une sélection classique ;
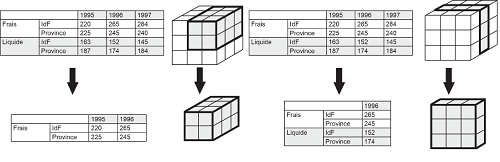
- Pivoter (rotate ou swap) : permet d'interchanger deux dimensions ;
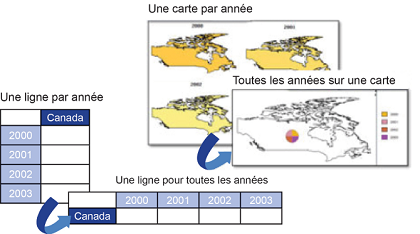
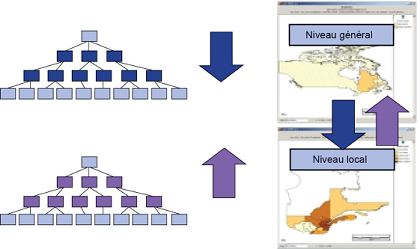
- Remonter (roll-up) : synthétise les informations en fonction d'une dimension. Par exemple, sur la dimension géographique, il s'agirait de passer du niveau département au niveau région ;
- Forer (drill-down) : il s'agit de l'inverse du (drill-up), on « zoome » sur une des dimensions (de la région au département) ;
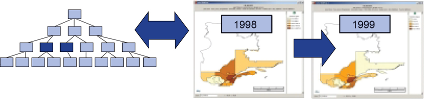
- Forer latéralement (drill-accross) : en restant au même niveau de dimension, permet de changer l'une des valeurs. Par exemple, passer de l'année 1998 à l'année 1999. Le forage latéral sur une dimension spatiale peut paraître aussi simple, si l'on considère que l'on passe, par exemple, d'un département à un autre. On peut s'interroger sur la pertinence de passer de l'Ain à l'Aine. Ne serait-il pas plus pertinent de rester dans la région ? Ou de considérer des critères de voisinage ?
- Percer (drill-through) : permet d'accéder au détail des informations, lorsqu'on ne dispose que de données agrégées (possible uniquement avec Hybrid OLAP).
L'architecture d'un système OLAP peut se décliner sous plusieurs formes, selon la technologie utilisée. On peut rencontrer des approches sans serveur OLAP, il s'agit alors de bases de données relationnelles, où rien n'est nativement prévu pour l'informatique décisionnelle. Il faut alors que la requête, construite dans le langage SQL (Structured Query Language), fasse état des agrégations. Ceci demande des compétences spécifiques, que tous les analystes n'ont pas forcément. L'approche ROLAP (Relationnal OLAP) est aussi basée sur une BDR, mais simulant une structure multidimensionnelle.
L'approche MOLAP (Multidimensional OLAP) est optimisée, comme son nom l'indique, pour l'analyse multidimensionnelle dont elle en gère la structure de manière physique.
HOLAP (Hybrid OLAP) est un croisement des approches MOLAP et ROLAP. Les données détaillées sont stockées dans une BDR tandis que celles agrégées le sont dans une BDM.
III-E. Outils de visualisation▲
Les outils de restitution sont la partie visible offerte aux utilisateurs. Par leur biais, les analystes sont à même de manipuler les données contenues dans les entrepôts et les marchés de données. Les intérêts de ces outils sont l'édition de rapports et la facilité de manipulation. En effet, la structure entière du système décisionnel est pensée pour fournir les résultats aux requêtes des utilisateurs, dans un temps acceptable (de l'ordre de quelques secondes), et sans connaissance particulière dans le domaine de l'informatique. Généralement, les outils offrent des facilités de manipulation, comme le « glisser-déposer », permettant une prise en main rapide, intuitive et conviviale.
III-F. Métadonnées▲
Les métadonnées, présentes à tous les niveaux, permettent de connaître les données, qu'elles soient brutes ou transformées. Moriarty et Greenwood ont déclaré, en 1997, que « les métadonnées sont aussi essentielles aux usagers que ne le sont les données elles-mêmes ». Elles décrivent le schéma de l'entrepôt, ainsi que l'ensemble des règles, des définitions, des transformations et des processus qui sont appliqués à chacune des données. Il y a deux types de métadonnées :
- Structurelles : décrivant la structure et le contenu de l'entrepôt (aussi appelées métaschéma) ;
- Accessibilité : permettant le lien entre l'entrepôt et les utilisateurs (description des données).
IV. Sources▲
Il se peut que certaines sources aient disparu depuis leur consultation. J'ai sauvegardé une copie de la plupart d'entre elles, si besoin, je peux les produire, sous réserve de l'accord de leurs propriétaires respectifs.
- Gilles Lebrun, Christopher Charrier. 2008. Informatique Décisionnelle. Cours DEST CNAM UE NFE115.
- Andreas Meier. 2006. Introduction pratique aux bases de données relationnelles. Seconde édition. (pages 197 à 203).
- Yvan Bédard, François Létourneau, Bernard Moulin. 1998. Perspectives d'utilisation du concept d'entrepôt de données pour les géorépertoires sur Internet.
- Claire Noirault. Novembre 2006. Business Intelligence avec Oracle 10g : ETL, Data warehouse, Data mining, rapports\x{0085}
- Thérèse Rougé-Libourel. 2008. Entrepôts de données spatiales OLAP et SOLAP.
- Bernard Lupin. Septembre 2007. Osez OLAP \x{0096} Les bases de données OLAP par l'exemple.
- Benoît Le Rubrus. Juin 2009. Capacité de rendu cartographique autour des technologies SOLAP. Épreuve TEST CNAM UE ENG111.
- Didier Donsez. Janvier 2006. Principes et architectures des entrepôts de données.
- Adrien Gabriel, Elias Ohayon. 2008. Les outils décisionnels: description de l'offre commerciale et Open Source.
- Yvan Bédard. OLAP et SOLAP : notions avancées des bases de données SIG.
- Eric de Malleray. 24 février 2008. Métadonnées et analyses multidimensionnelles à travers les hypercubes. Mémoire École Nationale Supérieure des Mines de Nancy \x{0096} LORIA
- Frédérique Peguiron, Odile Thierry. 2005. À propos d'un entrepôt de données universitaire : modélisation des acteurs et métadonnées.
V. Remerciements▲
Je tiens ici à remercier l'équipe de Developpez.com pour ses relectures attentives et ses suggestions, et en particulier KalyParker, Claude Leloup et bifconsult.