


I. Objectifs du document▲
OpenBizz est la Société de Services en Logiciels Libres (SSLL) du groupe UMANIS.
Notre mission est de proposer aux entreprises une alternative logicielle forte en proposant l'intégration de composants open source dans leur SI, des couches infrastructure (OS, messagerie, LDAP) jusqu'aux couches métiers (BI, CRM, ERP, SOA, GED, ECM, portail collaboratif...).
Nous accompagnons nos clients dans leur réflexion open source, qu'elle relève d'une démarche de maîtrise des coûts ou d'une volonté d'assurer efficacement l'interopérabilité des composants du SI.
Créé en 1991, Umanis est une société de conseil et d'ingénierie spécialisée en Business Intelligence, Gestion de la Relation Client (CRM) et en E-Business. Umanis, un des leaders français dans ces domaines, accompagne ses clients sur la globalité de leurs projets informatiques : conseils, réalisation, intégration, Tierce Maintenance Applicative et formation
En 2007, le Groupe Umanis a réalisé un Chiffre d'Affaires de 60 millions d'Euros et compte parmi ses 400 clients actifs des grands comptes internationaux, nationaux et régionaux. Avec près de 1000 collaborateurs, Umanis est implanté à Aix en Provence, Lille, Lyon, Metz, Nantes, Paris, Pau, Toulouse, Tours. Reconnu pour son expertise technologique et fonctionnelle, le Groupe Umanis est partenaire des plus grands éditeurs de logiciels du marché.
www.openbizz.frwww.openbizz.fr
www.groupeumanis.comwww.groupeumanis.com
Ce livre blanc intitulé « Restituer, Analyser et Piloter : Evaluer les opportunités Open Source » traite au sein de la chaîne décisionnelle des aspects de reporting, analyse, pilotage et distribution de l'information.
Nous avons souhaité y orienter la thématique plutôt que d'aborder de manière large mais superficielle l'ensemble des aspects relevant de la BI.
Ce livre blanc ne traitera donc pas des autres aspects importants de la chaîne décisionnelle, à savoir les ETL et base de données. Ceux-ci relevant plus des moyens que des usages.
Il ne traite pas non plus du Datamining pour deux raisons : c'est une étape complémentaire dans la business intelligence qui n'interpelle pas à ce jour tous les secteurs d'activité et ce sujet mérite à lui seul une livre blanc dédié.
Quant au processus d'élaboration budgétaire, qui s'apparente à une discipline de la business intelligence tout en étant au coeur de l'activité opérationnelle, il n'est pas abordé en tant que tel mais mis en avant sur une des solution OLAP que nous présentons.
Ce livre blanc abordera dans des chapitres dédiés chaque problématique (restitution, analyse, pilotage et industrialisation) sous l'angle de la MOE (installation, conception, production et exploitation) et sous l'angle MOA (usages).
Nous y présenterons le panel des outils disponibles au moment de la rédaction. Outils que nous avons eu l'occasion d'intégrer pour le compte de nos clients ou pour lesquels nous avons complété notre savoir faire en procédant à des bench sur nos plates-formes, avec des environnements de données significatifs.
C'est pourquoi tous les outils disponibles ne sont pas décrits, certains d'entre eux ne nous semblant pas capables d'assurer à court ou moyen terme, les besoins qu'ils sont censés adresser. Certains ne nous étant pas encore suffisamment familiers non plus !
Nous présentons en toute objectivité, l'ensemble de notre analyse sur les outils BI Open Source dans les quelques pages qui suivent.
Bonne lecture !
II. Introduction▲
II-A. Rappel des principales briques du SI fonctionnel▲
Le thème « Consommer, Analyser et Piloter » est en correspondance avec les pratiques actuelles de la business intelligence. Ces trois notions correspondent à des usages qui se veulent différents de par la nature des acteurs et de leur responsabilité dans le dispositif d'entreprise.
Quand on examine les services décisionnels impliqués dans les entreprises, ceux-ci sont déterminés sous cette triple approche :
II-A-1. Restitution▲
De plus en plus intégrée dans les dispositifs métiers opérationnels, la consommation d'information « business intelligence » concerne un large scope d'utilisateurs au sein des entreprises. Basée directement sur les outils de production ou en aval d'une chaîne décisionnelle (nous de traitons pas ici des apports de la chaîne décisionnelle ni des alternatives existantes), le besoin reste le même : Disposer d'informations chiffrées sur son activité, sur un pas temporel. Que ce soit sur des indicateurs de type flux (volume entre deux dates) ou de type stock (volume à date).
Ces usages s'inscrivent dans un pilotage fin et industrialisé de l'activité rendu nécessaire par l'envergure de l'activité, la tension de la concurrence ou encore la rationalisation des ressources disponibles pour maximiser la profitabilité. En cela ils concernent une grande proportion des personnels de l'entreprise et à tous les niveaux de la chaîne de responsabilité.
Il est commun de distinguer trois modes de restitution, matérialisés par des rapports aux nuances suivantes :
Rapport statique : il s'agit d'un rapport dont la structure est figée tant en termes de présentation que du périmètre des données présentées. Il présente l'avantage d'être généré en dehors du temps de travail de l'utilisateur et d'être consommable instantanément.
Par exemple, l'acheteur logistique d'une plateforme de commerce voudra disposer de manière hebdomadaire d'un rapport présentant l'évolution de la qualité de service de ses prestataires logistiques (capacité à délivrer la quantité dans les délais et la qualité attendue) afin de peser sur les négociations futures ou établir les pénalités.
Rapport dynamique : il s'agit d'un rapport ayant une structure de présentation semi statique au sein duquel le périmètre des données peut varier. Cela en offrant à l'utilisateur final la possibilité de choisir les valeurs de paramètres dynamiques intégrés dans le rapport. Cela présente l'avantage indéniable de disposer d'une grande amplitude sur les rapports finaux puisque à partir d'une même structure de rapport on pourra par exemple aussi bien générer un rapport de comparaison annuelle qu'un rapport de comparaison trimestrielle. La notion de paramètre implique cependant d'interroger la BDD ce qui dégrade l'instantanéité.
Par exemple, un responsable commercial régional travaillant pour une société de service en recrutement voudra consulter un rapport d'alerte de consommation (nb d'entreprises clientes n'ayant pas consommé depuis X mois telles offres) en sélectionnant un ou plusieurs codes d'activité INSEE et tout ou partie des offres de service proposées par sa société.
Rapport Ad hoc : il s'agit d'un rapport librement aménagé par l'utilisateur final. Il aménage les données qui l'intéressent dans une structure type tableau ou graphique en définissant le périmètre de consultation de ses axes et indicateurs. Cette approche nécessite que soit mis en place une « couche métier » (ou semantic layer) d'accès aux données. Cette couche permet de présenter à l'utilisateur une approche fonctionnelle des données et de leur relation, affranchissant ce dernier de la complexité des BDD et du langage SQL. Concrètement, les données sont regroupées au sein de thématiques métiers et reliées entre elles selon cette même logique métier. L'utilisateur n'a plus qu'à sélectionner ses données et les disposer dans son rapport. La encore, la volonté de l'utilisateur se traduit en une sollicitation de la base de données avec une performance d'affichage variable selon la complexité de la demande.
Par exemple, un chargé d'études au sein d'une société de services immobiliers voudra composer un rapport mettant en scène un nouvel indice illustrant mieux la tendance du marché des bureaux en IDF.
Pour ces trois aspects de la restitution, l'open source propose des solutions sous formes de composants intégrés ou non. Nous vous proposons de les découvrir dans la suite du document.
II-A-2. Analyse▲
Au-delà de l'activité qu'il faut surveiller à tous les échelons opérationnels (pour laquelle les services de restitution remplissent parfaitement leur rôle), il appartient à certains niveaux de management de comprendre plus profondément les mécanismes influant sur cette activité. Il s'agit par exemple de rechercher les causes d'une inflexion afin de mettre en place les mécanismes managériaux, organisationnels ou décider des investissements en vue de contrôler les facteurs déterminants les évolutions de l'activité.
Pour cela, le manager doit disposer d'une structure plus souple d'interrogation des données. Il doit pouvoir de manière libre naviguer dans les données sans à priori initial plus que la simple découverte. Sa navigation peut se faire de manière croisée (interroger la valeur de son indicateur de satisfaction client réparti selon la géographie, le temps et décliné par produit par exemple) et de manière ascendante / descendante en jouant sur le niveau de granularité des axes métiers (vision niveau mois, Europe, famille de produit puis mois, France, famille de produit en remontant ensuite sur une consolidation annuelle etc…)
Un des intérêts reconnus réside dans la capacité à trouver rapidement l'origine, la cause d'un phénomène. Par exemple, l'origine d'une inflexion des ventes constatée à un niveau agrégé (monde, annuel, gamme de produit) peut être identifiée par une navigation dans les niveaux plus fin de la géographie, des périodes ou des produits, aboutissant à situer une partie importante du problème au niveau d'un produit en particulier, d'un mois en particulier et enfin d'une structure commerciale en particulier.
Cette approche est volontairement théorique et non généralisable. En effet, on trouvera certaines catégories d'utilisateurs opérationnels qui peuvent profiter des services offerts pour effectuer leur travail au quotidien. Ca peut être le cas pour un département marketing qui cherchera à comprendre les résultats de sa campagne et qui pour cela trouvera un intérêt certain à manipuler des données disponibles dans un format multidimensionnel. En fait, elle peut être considérée comme un prolongement du reporting ad hoc.
Il est commun d'appeler « moteur OLAP » l'outillage permettant ce service.
Un moteur OLAP (autrement appelé multidimensionnel) permet à l'utilisateur d'accéder à un environnement fournissant de manière quasi instantanée la valeur des indicateurs au croisement des axes d'analyses. L'utilisateur sélectionne de manière conviviale les axes, le niveau sur les axes et les indicateurs qu'il veut y décliner. Ce système offre des fonctions natives de navigation dans le détail ou dans la consolidation des valeurs.
II-A-3. Pilotage▲
Les cadres dirigeants ont des besoins complémentaires. La surveillance de l'activité, non plus au niveau de son delivery opérationnel, mais dans sa capacité à remplir ses objectifs stratégiques, amène à considérer un outillage spécifique.
Les tableaux de bords du pilote (on entendra les termes associés de KPI, Dashboard, Balanced scorecard) sont des formats agrégés de présentation de contenu. Ils mettent en scène les indicateurs clés et les objectifs stratégiques en les confrontant. Très visuel, le tableau de bord permet de savoir rapidement si l'entreprise est en avance ou en retard sur son plan stratégique.
II-B. Les approches décisionnelles BI Open Source▲
II-B-1. Les solutions spécifiques▲
Les premiers composants OpenSource diffusés n'avaient pour objectif que de rendre un service. Sont donc souvent absents de l'approche les notions d'authentification, de définition du périmètre suivant l'utilisateur.
Ces solutions permettront la production du reporting statique, l'analyse au moyen de cubes OLAP.
Optimisés pour le service à rendre, ces composants stables et pérennes sont les briques essentielles des suites.
II-B-2. Les suites BI▲
Les suites vont plus loin, permettant l'agrégation de composants dans un portail dans un premier temps, puis intégrant la gestion de liens entre eux.
Le portail permettra une gestion centralisée des accès, avec définition du périmètre utilisateur selon son profil.
Les mécanismes de workflow des portails dédiés vont permettre le reporting de masse.
Les suites offrent en plus les composants dédiés aux utilisateurs non techniques, leur permettant de définir et de produire le reporting ad-hoc.
Certaines suite sont complétées par des outils techniques, permettant à la MOE la conception des rapports ou des axes d'analyse des cubes, et facilitant ensuite le déploiement automatisé des fichiers de configuration directement dans la plateforme mise à disposition des utilisateurs finaux.
II-B-3. Guide de lecture du document▲
Dans ce document, nous préciserons pour chacun des outils étudiés, les besoins couverts, mais aussi les contraintes afférentes, en termes de pré requis techniques à la mise en oeuvre, les compétences techniques nécessaires, la conduite de changement possiblement induite.
Nous préciserons la licence, les différences entre celles-ci impliquant parfois des contraintes légales à respecter.
Selon nos contacts avec les « éditeurs » ou « mainteneurs » des solutions, nous avons indiqué les développements futurs ou « roadmap » connues.
Un tableau, tel qu'en exemple ci-dessous, reprend une synthèse des éléments abordés et introduit quelques commentaires et notre retour d'expérience sur la mise en oeuvre de la solution.
| Item | Type d'item |
|---|
| Nom de l'outil |
|---|
| Description succincte |
| Public |
|---|
| Services concernés par l'usage, population |
| Pré-requis | - Pré requis techniques - Compétences nécessaires à la mise en oeuvre ou à l'usage |
| DESCRIPTION |
|---|
| - Description synthétique de la mise en oeuvre o Complexité de la mise en oeuvre de la solutiono Poste de travail ou mode partagé (mode web)o …. - Description synthétique de l'usage o Complexité d'appropriation de la solutiono Description de la couverture fonctionnelle |
| Licence | Indication du type de licence, du support disponible, des coûts à prévoir (selon informations disponibles) |
|---|
| Notes | Commentaires |
|---|
Nous conclurons chaque chapitre par une synthèse des outils et leurs indications métier.
Le tableau suivant présente une brève description des distinctions principales entre les différentes licences open source évoquées dans ce document. Nous n'avons pas souhaité aborder plus profondément le sujet, de multiples littératures sur le sujet étant déjà disponibles sur le web.
| Licences | Description synthétique |
|---|---|
| GPL | General Public License : Code ouvert, usage libre, modification et évolution du code possible, distribution libre avec pour seule contrainte de propager le type de licence. (notion de copyleft). GPL est restrictif quant à l'assemblage de codes logiciels. Seuls les codes logiciels compatibles GNU GPL peuvent être assemblés. |
| CPL | Common Public License : La différence essentielle avec la GPL est la liberté offerte aux personnes ayant apporté des évolutions majeure au produit d'attribuer la licence de leur choix sur ces évolutions. Cette licence a été mise en place pour la plateforme Eclipse, permettant ainsi à IBM d'en commercialiser une version propriétaire. |
| EPL | Eclipse Public License : La différence essentielle avec la GPL est la liberté offerte aux personnes ayant apporté des évolutions majeure au produit d'attribuer la licence de leur choix sur ces évolutions. Elle est dérivée de la CPL (Common Public License) originelle qui comportait certaines mentions favorables à IBM. |
| MPL | Mozilla Public License : Grandes similitudes avec la licence GPL. Elle est cependant un peu moins restrictive quant à sa compatibilité avec d'autres licences (dans les cas de mixité de programme). La notion de copyleft demeure mais seulement sur la partie MPL de l'assemblage |
| LGPL | Lesser General Public License Grandes similitudes avec la licence GPL. Elle est cependant un peu moins restrictive quant à sa compatibilité avec d'autres licences (dans les cas de mixité de programme). La notion de copyleft demeure mais seulement sur la partie LGPL de l'assemblage |
NB : rappelons qu'en droit français, seules les licences rédigées en français sont reconnues valides par le législateur. Or il n'existe pas de traduction « officielle » de la GNU GPL. Mais, un jugement du 28 mars 2007 (TGI Paris, 3ème chambre, 1ère section, 28 mars 2007, Educaffix c/ CNRS, Université Joseph Fourier et autres) expose un premier cas de jurisprudence relative à une licence GNU GPL v2. On lira avec intérêt l'analyse faite de ce jugement par le cabinet CAPRIOLI à l'URL :
En Allemagne, la loi allemande a validée en 2004 les principales clauses de la GNU GPL
Pour l'Europe, notons que s'est tenue la conférence « EOLE » (European Opensource Lawyers Event) le 24 septembre 2008, organisée dans le cadre de la manifestation « Paris, Capitale du libre »
III. Les solutions spécifiques de restitution▲
Plus exactement, le terme restituer représente un moyen plutôt qu'un usage. Il est le moyen technique, applicatif qui permet la consommation d'information à valeur décisionnelle (i.e., le client consommateur doit être en mesure de définir (ou choisir) l'action appropriée à la lecture de l'information qui lui est fournie).
Il est cependant commun de synthétiser sous ce seul terme les usages représentés par la consommation d'informations statiques, pré paramétrées ou encore ad hoc.
III-A. Rapports statiques ou dynamiques▲
Pour rendre disponibles des rapports statiques ou dynamiques auprès des utilisateurs, il faut des outils offrant des fonctions de conception et de production de rapports.
Pour cet usage, l'open source propose deux composants majeurs que sont Birt et Ireport couplé avec JasperReport.
Les plateformes BI que nous détaillons au sein du § 7 sur l'industrialisation des Systèmes d'Information Décisionnelle mettent généralement en oeuvre IReport ou BIRT. La plateforme Pentaho intègre en plus une solution dédiée, alternative à Birt et JasperReport.
Les critères permettant d'évaluer des services BI sont nombreux et peuvent être déclinés sur un niveau de précision tel qu'il ne contribuerait pas à leur lisibilité dans le cadre de ce livre blanc. Nous nous satisferons d'un niveau de présentation agrégé de ces critères afin de positionner chacune des offres de manière claire.
Pour les rapports statiques ou dynamiques, les fonctions importantes sont listées dans le tableau suivant
| Fonction majeure | Description |
|---|---|
| Capacité à intégrer des fonctions de traitement des données (arithmétiques, statistiques, date, texte, numériques …) | Les données brutes ainsi que des données valorisées (issues de calculs sur les données brutes) peuvent être stockées en BDD. Ceci implique une anticipation par les utilisateurs finaux sur les données à restituer, ainsi qu'une intervention de la MOE. Pour d'autres types d'indicateurs (indicateurs non linéaires) ou pour répondre à un besoin immédiat, les outils de restitutions doivent intégrer des fonctions de traitement de données. |
| Mise en forme (rupture, groupement, saut de page, tri, mise en forme conditionnelle, entête et pied de page) | Pour rendre l'information visible, s'assurer qu'elle sera perçue à sa juste valeur, celle-ci doit être lisible. De même pour être partagée, communiquée vers des tiers, le rendu doit être structuré. Il est donc important de considérer les capacités de mise en forme des outils. Aérer l'information, mettre en évidence les groupements, professionnaliser l'aspect sont autant de points importants |
| Vision de l'information (Liste, Tableau croisé, Graphes à barre, radar, histogramme …) | La représentation de l'information impacte considérablement la rapidité d'appréhension et de digestion d'une information. Selon ce que sont censées illustrer les données, ou encore le nombre d'entrées qu'elles présentent, lechoix d'un format de restitution adapté doit être possible. |
| Mise à disposition (formats d'exports, mail, portail web, envoi en masse, planification…) – | La disparité des environnements accessibles aux utilisateurs nécessite de prévoir une distribution selon plusieurs formats ou moyens |
| Sécurité (droits sur les rapports, droits sur les données avec filtre data en fonction de l'utilisateur permettant de distribuer un même rapport avec des périmètres données différents…) | Le caractère confidentiel des données pour des raisons de management, de concurrence ou autre nécessite d'apporter des moyens pour restreindre les informations offertes selon les prérogatives du consommateur |
| Paramétrabilité (invites utilisateurs - saisie libre/ référentiel, invite en cascade,..) – | Coupler un rapport statique avec des paramètres permet de le rendre dynamique. L'utilisateur n'est pas contraint à consulter un périmètre figé mais peut jouer sur les paramètres pour afficher un périmètre différent (en terme de période, produit, zones de marché etc…) |
| Fonctions avancées (filtre récapitulatif, indicateurs en ligne, accès multisource, audit d'utilisation…) | Sans être primordiales, un certain nombre de fonctions avancées peuvent rendre de grands services aux MOE ou MOA |
| Capitalisation (enregistrement de requêtes, de modèles, de vues réutilisables…) – | Utile pour augmenter la productivité des ressources et ainsi favoriser les personnels (MOE ou MOA) à consacrer leur temps à des tâches à plus forte valeur ajoutée |
Les outils présentés sont articulés autour de deux besoins différenciés :
- La conception du rapport (format, logo, présentation des données, extraction des données,…) qui implique une connaissance technique du format de stockage des informations.
- La production du rapport qui sera généré à la demande (avec éventuellement une précision apportée au périmètre ou au format de sortie) ou bien automatisée (le périmètre est définitivement déterminé, ainsi que les destinataires et le format de sortie)
Conception du rapport
Dans le reporting statique, cette tâche de conception est assignée à une équipe technique qui va mettre en place la connexion à la base, élaborer les requêtes SQL, concevoir graphiquement le canevas du rapport.
Cette première étape va être réalisée au moyen d'un outil graphique déployé sur le poste client, au moyen d'une interface graphique Java.
Les outils présentés produisent un fichier au format « xml » contenant les éléments nécessaires à l'extraction des données, leur transformation éventuelle avant le positionnement dans le document à produire.
Production du rapport
La production du rapport final met en oeuvre des librairies Java qui vont parcourir le fichier au format « xml » produit par l'outil d'élaboration. A la rencontre d'un champ à remplir, l'outil de production exécute la requête SQL associée, puis l'alimente avec les données extraites.
Il est possible de planifier l'exécution de ce rapport, ou bien de l'intégrer à un portail BI, permettant à l'utilisateur de définir des paramètres.
III-A-1. iReport – JasperReport▲
La conception du rapport se fera au moyen de l'outil iReport, une interface dédiée à la conception de rapports JasperReport.
La restitution, se fera depuis JasperReport, sous forme de librairies intégrées dans un portail BI. Cette intégration permet la définition d'accès aux bases de données dans le portail et donne la capacité à l'utilisateur final de compléter la définition du périmètre des données du rapport à produire.
III-A-1-a. Conception par IReport▲
iReport permet la composition du rapport. Les éléments graphiques, les zones de données, sont définis simplement par « glisser-déposer ». L'utilisateur indique les paramètres de connexion à la base de données pour valider les données et le rendu final du rapport. L'interface est simple et intuitive. Elle intègre un « query designer » qui permet de construire graphiquement une requête. Les clés sont automatiquement reconnues et les jointures s'opèrent sous forme de lien automatique.
Lorsque que la requête est constituée, les champs remontés peuvent être placés dans les zones de restitution avec la souris. On choisit les paramètres de mise en page, puis on lance la compilation. Dans un premier temps, celle-ci produit un fichier « .java » à partir du descripteur « .jrxml ». Ensuite, ce « programme » est exécuté en utilisant les librairies JasperReport et les paramètres d'accès aux bases de données. L'exécution de ce programme génère le rapport final.
Il est possible d'ajouter du code Java dans le document pour produire la conversion de type de données ou pour ajouter des opérateurs sur des champs remontés. Cette capacité permet l'optimisation de la mise en forme ou l'ajout de champs calculés.
Un plugin permet un interfaçage direct avec JasperServer, la plateforme BI de JasperSoft dont iReport et JasperReport sont deux outils. Grâce à ce plugin, le déploiement du format du rapport validé est immédiat depuis iReport.
Un autre plugin permet de consulter les rapports installés dans la plateforme BI SpagoBI. Il en permet la modification, à partir du moment où le fichier « .jrxml » a été déployé précédemment dans la plateforme.
iReport ne peut gérer qu'une seule source de données SQL pour toutes les requêtes du rapport. Une deuxième requête peut être utilisée pour produire le graphe, indépendamment de la première utilisée pour la restitution de données sous forme de tableau.
Ci-dessous une copie d'écran de conception sous iReport.
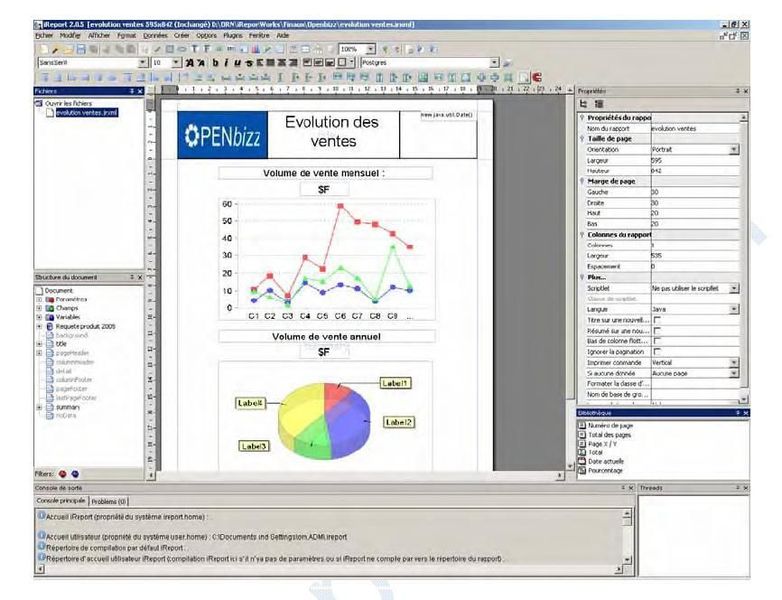
L'interface iReport est un client « lourd » sous Java. Aucune compétence technique complexe n'est requise pour cette installation, il faudra juste veiller à disposer d'une Java Virtual Machine installée sur le poste de développement.
Les connexions aux bases de données se feront au moyen de drivers JDBC (pendant Java des connecteurs ODBC sur les plates formes Microsoft), qui devront être installés dans le répertoire des librairies de l'outil.
Pour aller plus loin dans la conception de rapports, des compétences en langage Java pourront être utiles, afin de développer des méthodes de remplissage de champs ou de transtypage de données.
| Item | CONCEPTION |
|---|
| iReport v3.0.0 |
|---|
| P ermet la conception graphique d'un rapport. Produit un fichier de définition au format « jrxml » |
| Public | - MOE : Permet la conception de reporting généré par les librairies JasperReport - Utilisateurs : Il est possible de l'utiliser comme outil de production de rapports. |
| Pré-requis | - Client « lourd » supposant une JVM - Paramètres de connexion à la base de données - Langage SQL (pour la conception de requêtes) - Langage Java (pour affiner la conception) - Langage XML (pour comprendre le fichier « jrxml » produit) |
| DESCRIPTION |
|---|
| - Interface graphique sous Java, indépendante de la plate forme. Elle permet de produire un rapport et/ou un fichier de description au format « jrxml », utilisable dans une plate forme.o Interface intuitiveo Mode visualisation permettant de pré visualiser le rapport final - Conception en mode « drag & drop »o Les outils et les champs de formats différents se glissent et se dépose sur la page de conception La définition de la connexion à la base de données est extérieure au fichier de conception produit. |
| Licence | Licence LGPL Documentation et exemples accessibles depuis le site de JasperForge Librement téléchargeable sans coût de licence Supports et formations payants (proposés par les SSLL) |
|---|
| Notes | Notes Les paramètres de connexion à la base de données sont extérieurs à la définition du rapport. Ce |
|---|
III-A-1-b. Production par JasperReport▲
JasperReport se présente sous forme de librairies Java, accessible depuis une application ou un projet J2EE.
Le fonctionnement est « transparent » pour l'utilisateur final, l'interface intègre les librairies d'exécution.
Elles présupposent l'usage d'une interface (outil Java, portail ou plateforme BI) qui va permettre la définition des paramètres de connexion aux données et le mode de production du rapport.
| Item | PRODUCTION |
|---|
| JasperReport v3.0.0 |
|---|
| Librairie de production du rapport défini au moyen de « iReport » (cf. ci-dessus) |
| Public | - Utilisateurs : Génère le rapport à partir du fichier de conception « jrxml » transmis en paramètre |
| Pré-requis | - JVM - Paramètres de connexion à la base de données - Langage SQL (pour la conception de requêtes) - Langage Java (pour affiner la conception) - Langage XML (pour comprendre le fichier « jrxml » utilisé) |
| DESCRIPTION |
|---|
| - La librairie JasperReport permet de produire les fichiers de reporting conçu depuis iReport. o Intégrée dans un portail ou une plateforme BI : .. celui-ci fournit les paramètres de connexion à la base de données .. il est possible de planifier l'exécution de la production .. il est possible de permettre à l'utilisateur d'affiner le périmètre sur lequel construire le rapport - Exécution transparente pour l'utilisateur final, leur mise en oeuvre ne demande aucune connaissance particulière. Elles doivent être accessibles (dans le chemin des librairies) à l'application qui les utilise. o Les rapports sont d'un niveau de qualité correct, le rendu graphique s'améliorant à chaque évolution de la librairie |
| Licence | Il existe une version GPL et une version commerciale. |
|---|
| Notes | - Les librairies ne sont accessibles à l'utilisateur final qu'au travers une interface java, sous forme d'une application ou d'un portail BI. - Pas d'utilisation en mode « stand alone » - Production des graphes gérée par une librairie externe JFreeChart sous licence LGPL |
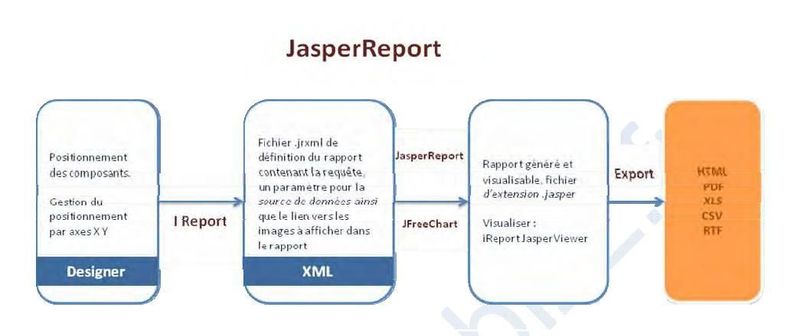
Schématisation des composants mis en oeuvre dans la production du fichier « jrxml »
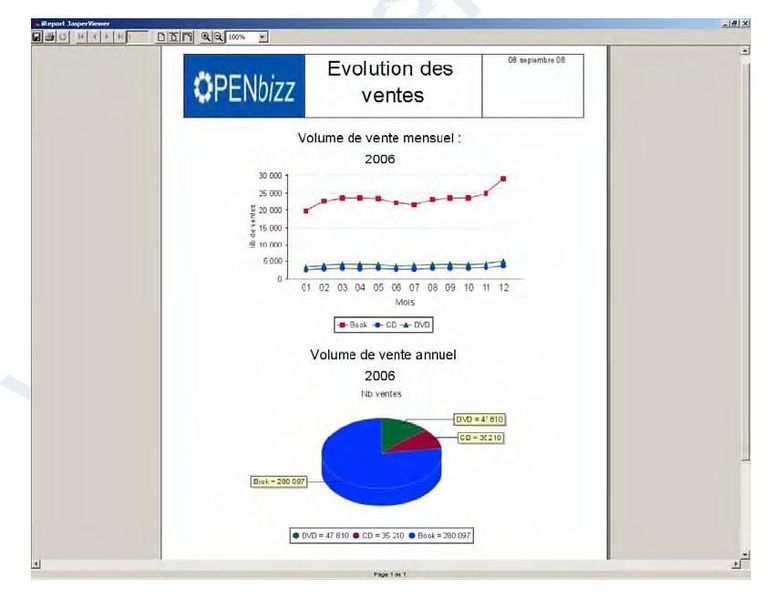
III-A-1-c. Restitution▲
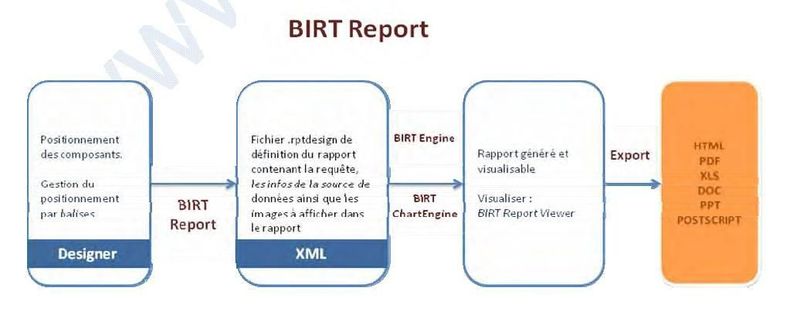
III-A-2. BIRT▲
L'interface BIRT (Business Intelligence Reporting Tools) est conçue sous Eclipse. A l'origine projet de la fondation Eclipse, la société ACTUATE en est maintenant co-sponsor. La solution permet, par « glisser-déposer », de composer un rapport. Tous les composants graphiques sont présents et comme avec iReport, le rapport se construit de manière intuitive.
III-A-2-a. Conception sous BIRT▲
Cette solution n'intègre pas de « query designer », outil permettant de construire graphiquement les requêtes. Elle permet par contre d'ajouter des filtres sur les données Le transtypage de données y est plus intuitif. Il n'est pas nécessaire de produire du code Java pour obtenir ce résultat. Il peut être obtenu par choix de fonctions aux noms explicites, à appliquer sur les données insérées dans le rapport. La solution permet l'usage de plusieurs sources de données, l'utilisation de plusieurs requêtes différentes, autant pour des données restituées sous forme de tableau que sous forme de graphiques.
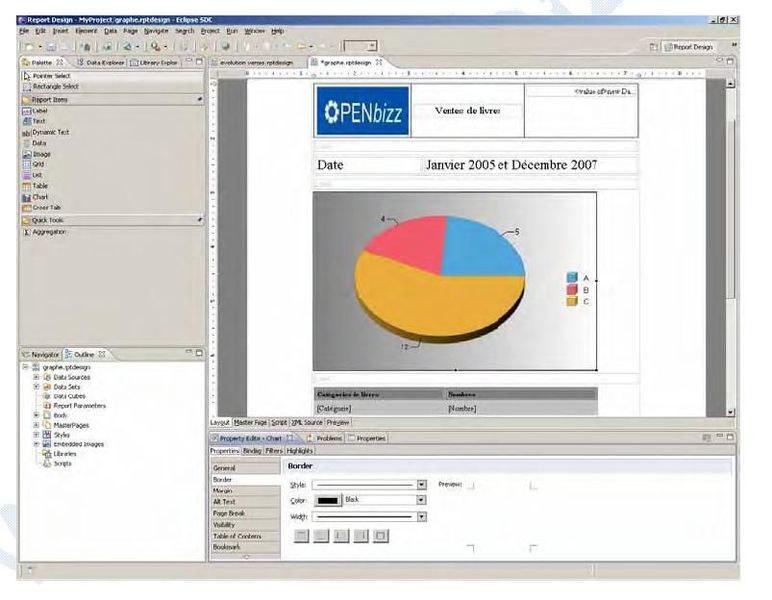
| Item | CONCEPTION |
|---|
| BIRT v2.3.0 |
|---|
| Interface graphique sous Eclipse, permettant la conception de rapports au format BIRT |
| Public | MOE : conception de reporting au format BIRT Utilisateurs : Il est possible de l'utiliser comme outil de production de rapports. |
| Pré-requis | - Client Eclipse en Java, nécessitant l'installation d'une JVM- Paramètres de connexion à la base de données- Langage SQL (pour la conception de requêtes)- Langage Java (pour affiner la conception) |
| DESCRIPTION |
|---|
| - Interface graphique sous Eclipse, indépendante de la plate forme. Elle produit un fichier de description au format « rptdesign » o Interface intuitive o Mode visualisation permettant de pré visualiser le rapport final - Conception en mode « drag & drop » o Les outils et les champs de formats différents se glissent et se déposent sur la page de conceptiono Les images (logo,…) ainsi que la définition de la connexion à la base de données sont inclus dans le fichier de conception produit |
| Licence | EPL (Eclipse Public Licence) Librement téléchargeable sans coût de licence |
|---|
| Notes | - Tous les éléments sont inclus dans le fichier « rptdesign » - La librairie de génération du graphe est propre à BIRT |
La société ACTUATE est co-sponsor du projet BIRT sous Eclipse. Cette société participe activement aux développements de BIRT Report et propose des produits non OpenSource additionnels suivants :
Actuate BusinessReport Studio : Portail décrit par Actuate comme permettant la conception de rapports « adhoc » et leur visualisation.
Actuate BIRT Designer & BIRT Designer Professional : Version « professionnelle » de BIRT Report
Actuate Information Objects : Permet la conception de vues métiers par la MOE, mis à disposition des utilisateurs de données fonctionnelles.
III-A-2-b. Production sous BIRT Report▲
La production se fait par l'usage de librairies paramétrées dans le fichier de description du rapport final. Les images, les accès aux bases de données étant définies dans ce fichier de description, la conception d'une application Java autonome exploitant les librairies et le fichier est simplifiée.
| Item | PRODUCTION |
|---|
| BIRT v2.2.0 |
|---|
| Affichage du rapport final et production de différents types d'export |
| Public | Utilisateurs : Affichage du rapport généré dans l'outil de conception ou dans le portail |
| Pré-requis | - JVM - Paramètres de connexion à la base de données - Langage SQL (pour la conception de requêtes) - Langage Java (pour affiner la conception) - Langage XML (pour comprendre le fichier « rptdesign » utilisé) |
| DESCRIPTION |
|---|
| - Les librairies BIRT permettent de produire les fichiers de reporting conçu depuis BIRT.o Intégrée dans un portail ou une plateforme BI :il est possible de planifier l'exécution de la productionil est possible de permettre à l'utilisateur d'affiner le périmètre sur lequel construire le rapport- Exécution transparente pour l'utilisateur final, leur mise en oeuvre ne demande aucune connaissance particulière. Elles doivent être accessibles (dans le chemin des librairies) à l'application qui les utilise. Les rapports sont d'un niveau de qualité correct, le rendu graphique dans certains formats d'export pourrait être amélioré |
| Licence | EPL (Eclipse Public License) |
|---|
| Notes | Rapport figé ou pré paramétré Rapports dynamiques permettant des interactions avec l'utilisateur |
Schématisation des composants mis en oeuvre dans la production du fichier « rptdesign »
IV-A-2-c. Restitution▲
III-A-3. Synthèse des outils de restitution▲
La solution JasperReport fait partie des premiers composants BI. Il a bénéficié d'apports de toute la communauté depuis l'année 2000. Sa conception en deux parties distinctes, d'un côté l'interface de conception iReport, de l'autre les librairies de production, le rendent flexible et intégrable dans de nombreux projets.
On le retrouvera donc dans toutes les plateformes BI, de SpagoBI à Pentaho en passant par JasperServer.
Une des limitations est qu'il est nécessaire de lui fournir les images et logos décrit dans le fichier de conception, ainsi que l'accès aux bases de données.
BIRT est lui aussi architecturé autour de librairies de production, mais son interface de conception et la production d'un descripteur autonome en permettent un usage autonome. Pour BIRT, seul le fichier de description est nécessaire, les images et le paramétrage d'accès aux données étant inclus dans celui-ci.
Le choix des outils entre BIRT et JasperReport sera donc guidé par l'usage :
- • Pour un rendu comparable, BIRT sera privilégié comme outil autonome.
- • Pour l'intégration dans un portail ou un développement spécifique, on préférera Jasper, dont les paramétrages sont plus accessibles.
- • Si de multiples sources de données doivent être agrégées dans le même rapport, on utilisera la solution BIRT, Jasper n'intégrant pas cette fonctionnalité.
- • S'ilest nécessaire d'avoir des rapports dynamiques contenant des interactions avec l'utilisateur, la solution BIRT sera plus adaptée.
D'un point de vue des critères, le tableau suivant présente les points forts des deux solutions
| Fonction majeure | iReport / JasperReport | Birt |
|---|---|---|
| Capacité à intégrer des fonctions de traitement des données (arithmétiques, statistiques, date, texte, numériques …) | Les fonctions disponibles sont celles offertes par la BDD sous jacente – peu de limite La programmation procédurale est aussi intégrable |
Les fonctions disponibles peuvent être gérées par Birt indépendamment des fonctions fournis par la BDD. La programmation procédurale est aussi intégrable |
| Mise en forme (rupture, groupement, saut de page, tri, mise en forme conditionnelle, entête et pied de page) – | Toutes ces caractéristiques de mise en forme sont prises en compte nativement dans iReport. | Toutes ces caractéristiques de mise en forme sont prises en compte nativement dans Birt Un rapport Birt peut être conçu de manière dynamique pour un usage sous forme de dashboard. |
| Vision de l'information (Liste, Tableau croisé, Graphes à barre, radar, histogramme …) | La vision de l'information est totalement paramétrable lors de la conception du rapport. | La vision de l'information est totalement paramétrable lors de la conception du rapport. |
| Mise à disposition (formats d'exports, mail, portail web, envoi en masse, planification…) – | Export possible en PDF, HTML, XLS, CSV, Txt, RTF, ODF. Parfaitement intégrable à un portail pour la diffusion de masse. Un simple remplacement de la librairie JasperReport permet de prendre en charge les nouvelles fonctionnalités. |
Export possible en PDF, HTML, XLS, DOC, PPT, POSTSCRIPT. Parfaitement intégrable à un portail pour la diffusion de masse. La mise à jour au sein d'un portail n'est pas un modèle de simplicité. |
| Sécurité (droits sur les rapports, droits sur les données avec filtre data en fonction de l'utilisateur permettant de distribuer un même rapport avec des périmètres données différents…) | Essentiellement gérée par le portail, dans la conception il faudra simplement spécifier les éléments paramétrables. | Essentiellement gérée par le portail, dans la conception il faudra simplement spécifier les éléments paramétrables. |
| Paramétrabilité (invites utilisateurs - saisie libre/ référentiel, invite en cascade,..) | La gestion des paramètres est intégrée à iReport ce qui permet, à l'exécution du rapport, de proposer un invite pour sélectionner le ou les paramètre(s). Pour une gestion des paramètres encore plus poussée il faudra utiliser les fonctions du portail. |
La gestion des paramètres est intégrée à BIRT et dispose de plusieurs options comme la saisie libre, la liste déroulante, la sélection multiple et la gestion des paramètres en cascade. La gestion des paramètres sert également à rendre le rapport dynamique à l'image des dashboards. Intégré dans un portail, une autre dimension de paramétrabilité peut être utilisée. |
| Fonctions avancées (filtre récapitulatif, indicateurs en ligne, accès multisource, audit d'utilisation…) | Beaucoup de points sont déjà gérés par le portail. iReport pêche tout de même quand il s'agit de l'accès multi source ou plutôt multi requête. Les rapports secondaires peuvent éventuellement palier à ce problème. |
Beaucoup de points étant déjà gérés par le portail, Birt offre la capacité d'accès multi source, les jointures entre plusieurs source de données et des fonctions de calcule entre des champs de base de données différentes, et tout ceci au sein du même rapport en plus de la gestion des rapports secondaires. |
| Capitalisation (enregistrement de requêtes, de modèles, de vues réutilisables…) – | Essentiellement géré par le portail. | Essentiellement géré par le portail. |
III-B. Rapports Ad Hoc▲
Pour qu'un utilisateur puisse créer son propre rapport, en supposant (ce qui représente la majorité des cas) qu'il n'a pas la connaissance pratique des modalités d'interrogation SQL des données, il a besoin qu'une représentation métier de ces données lui soit présentée.
Concrètement, stockage relationnel ne veut souvent pas dire grand-chose pour un utilisateur métier.
Pourquoi aurais je besoin de comprendre les contraintes techniques, de volumétrie, d'atomicité, de cardinalité et pleins d'autres bonnes raisons qui ont poussé les MOE à répartir les données dans des tables distinctes ? Surtout quand cette répartition signifie que je dois comprendre la notion de jointure entre les tables afin d'associer mes données entre elles…
Donc pour permettre une certaine liberté aux utilisateurs quant à leur besoin en terme de reporting, les couches métiers sont une réponse efficace (pour faire une analogie avec les éditeurs historiques, on parlera anciennement de « catalogue » chez Cognos puis de « framework », d' « univers » pour Business Objects ou encore d' « infomap » chez Sas)
Ce genre de service n'est pas offert à tous les utilisateurs, il n'est pas forcément non plus mis en place au sein de toutes les entreprises, certaines préférant que la DSI contrôle l'ensemble de la production des rapports mis à disposition des utilisateurs.
Les critères déterminants pour qualifier la pertinence des technologies des éditeurs sur cet aspect sont globalement les mêmes que ceux déterminés pour les rapports statiques.
Sauf qu'ils s'appliquent différemment.
Par exemple, la présence de fonctions de calculs nécessaire pour travailler les données, s'adressant à des utilisateurs ne peut plus être implémentée à l'aide de requêtes SQL ou de procédures type pgSQL (spécifique base PostgreSQL).
Elle doit devenir graphique, c'est-à-dire permettre à l'utilisateur de sélectionner une fonction présentée de manière littérale pour qu'il l'applique sur la donnée choisie.
La couche métier, dont la conception est assurée par la MOE, doit offrir des fonctionnalités élémentaires et d'autres de confort
| Outillage | Critères | Description |
|---|---|---|
| Outil de conception de la vue métier | Fonctions de design métier de la BDD | Importation des tables, renommage des champs techniques, classement de l'information en dossiers, création de jointure libre ou semi automatisé, gestion des boucles |
| Capacité à créer de nouvelles données calculées (à partir de celles importées de la base et offertes ensuite aux utilisateurs) – présence de fonctions de traitement des données (arithmétiques, statistiques, date, texte, numériques …) | Les données brutes, une partie des données valorisées peuvent être stockées en BDD mais tout ne peut être reporté sur la base. Pour des raisons d'anticipation (le process de modélisation et d'alimentation demeurant peu flexible) comme pour des contraintes naturelles (indicateurs non linéaires). Il est donc vital que la valorisation des données, leur préparation puisse aussi être prise en charge par les outils de restitution. Ainsi les fonctions de traitement de données ont leur utilité dans les outils | |
| Sécurité (droits sur les données) | Le caractère confidentiel des données pour des raisons de management, de concurrence ou autre nécessite d'apporter des moyens pour restreindre les informations délivrées | |
| Fonction de contrôle des utilisateurs | Afin de préserver la disponibilité des infrastructures, il est important de limiter certaines actions utilisateurs. Notamment les produits cartésiens ou les requêtes trop complexes. | |
| Outil de création des rapports Ad hoc | Capacité à intégrer des fonctions de traitement des données (arithmétiques, statistiques, date, texte, numériques …) | |
| Mise en forme (rupture, groupement, saut de page, tri, mise en forme conditionnelle, entête et pied de page) | pour rendre l'information visible, s'assurer qu'elle sera perçue à sa juste valeur, celle-ci doit être lisible. De même pour être partagée, communiquée vers des tiers, le rendu doit être structuré. Il est donc important de considérer les capacités de mise en forme des outils. Aérer l'information, mettre en évidence les groupements, professionnaliser l'aspect sont autant de points importants | |
| Vision de l'information (Liste, Tableau croisé, Graphes à barre, radar, histogramme …) | La représentation de l'information impacte considérablement la rapidité d'appréhension et de digestion d'une information. Selon ce que sont censées illustrer les données, ou encore le nombre d'entrées qu'elles présentent, il convient mieux de sélection un format de vision différent. Les outils doivent donc être dotés de modes de représentation différents | |
| Mise à disposition (formats d'exports, mail, portail web, envoi en masse, planification…) – | L'utilisateur créant son rapport peut souhaiter le mettre à disposition des autres utilisateurs. La disparité des environnements accessibles aux utilisateurs nécessite de prévoir une distribution selon plusieurs formats ou moyens | |
| Paramétrabilité (invites utilisateurs - saisie libre/ référentiel, invite en cascade,..) – | De même, l'utilisateur peut souhaiter rendre dynamique le rapport qu'il vient de créer. Il y ajoute alors des paramètres permettant de faire varier le périmètre de consultation des données affichées dans le rapport. | |
| Fonctions avancées (état d'avancement de la requête, annulation de requête, application d'une mise en forme différente sur le résultat d'une requête | Sans être primordiales, un certain nombre de fonctions avancées peuvent rendre de grands services aux utilisateurs. | |
| Capitalisation (enregistrement de requêtes, de modèles, de vues réutilisables…) | Utile pour augmenter la productivité des ressources et ainsi favoriser les personnels à consacrer leur temps à des tâches à plus forte valeur ajoutée |
Il n'existe pas de composants dédiés au reporting ad hoc. Ce service est offert de manière intégré par les différentes plates formes BI, Pentaho », « SpagoBI », « JasperServer » et « BPM Conseil » que nous présentons à partir du chapitre 7 sur l'industrialisation des SID.