IV-B. Présention de Pentaho Data Integration▲
Pentaho Data Integration est l'ETL de la suite décisionnelle Open Source Pentaho.
Cet ETL, « Kettle » à l'origine, est le fruit du travail de Matt Casters, un consultant BI qui l'a développé à
l'origine pour ses propres besoins au début des années 2000.
Courant 2006, Matt Casters rejoint la société Pentaho, et « Kettle » devient « Pentaho Data Integration ».
Les nouvelles versions s'enchaînent alors à un rythme soutenu. La prochaine version est la 3.0.2 qui doit sortir courant Février 2008.
Contrairement à Talend Open Studio, Pentaho Data Integration est un « moteur de transformation » ETL: les données traitées et les traitements à effectuer sont parfaitement séparés. (on parle de « meta-data driven » ETL)
Les traitements sont stockés dans un référentiel (repository) qui peut être soit au format XML (fichiers plats), soit dans une base de données (ce qui permet notamment le partage entre plusieurs designers).
Tout comme Talend Open Studio, de nombreux types de SGBD sont supportés (une trentaine) ainsi que tous les types de fichiers plats (Csv, délimité, Excel, XML).
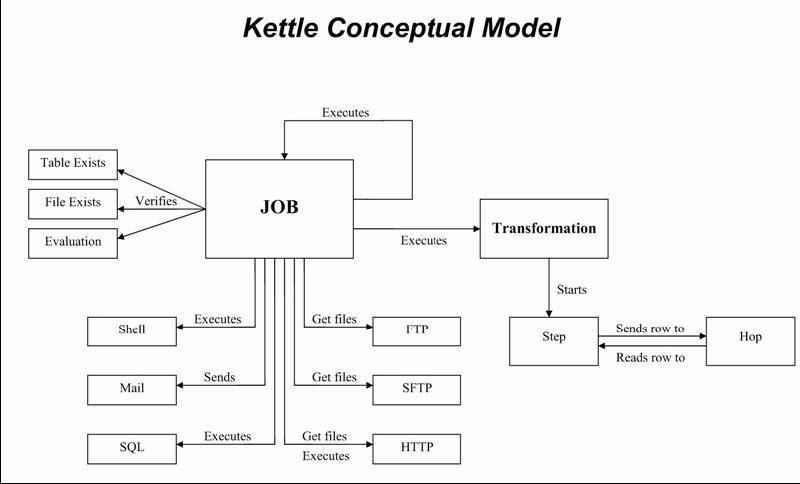
Pentaho Data Integration dipose d'une interface graphique « Spoon » (basée sur SWT), depuis laquelle on peut créer deux types de traitements :
- des transformations : celles-ci constituent les traitements de base d'intégration de données avec toutes les étapes (steps) nécessaires à l'extraction, la transformation, et le chargement des données.
- des tâches (jobs) : ceux-ci permettent le séquencement de plusieurs transformations avec des fonctionnalités plus orientés « EAI » : gestion des erreurs, envoi de mails de notification, transferts FTP/SFTP, exécution de scripts shell ou SQL, etc...
Caractéristiques de Pentaho Data Integration :
- Un produit sous licence GNU disponible sur plusieurs systèmes d'exploitation :

- Une suite de 3 composants: L'interface graphique « Spoon », les déclencheurs en mode batch pour les transformations (« Pan ») et les jobs (« Kitchen »).
- Une installation simple (un dossier à décompresser) => un environnement d'exécution JAVA 1.5 suffit
- La possibilité de prévisualiser les flux de données traitées, et ceci pour une étape donnée.
- La possiblité d'exécuter les traitements sur le poste local, un serveur distant, ou un ensemble de serveurs (exécution en « grappe »; clustering)
- La possibilité de logger les traitements dans une base de données spécifique.
- L'intégration parfaite avec la plate-forme décisionnelle Pentaho. Par exemple, les flux de données en provenance de l'ETL peuvent servir à alimenter des rapports ou des dashboards en temps réel.
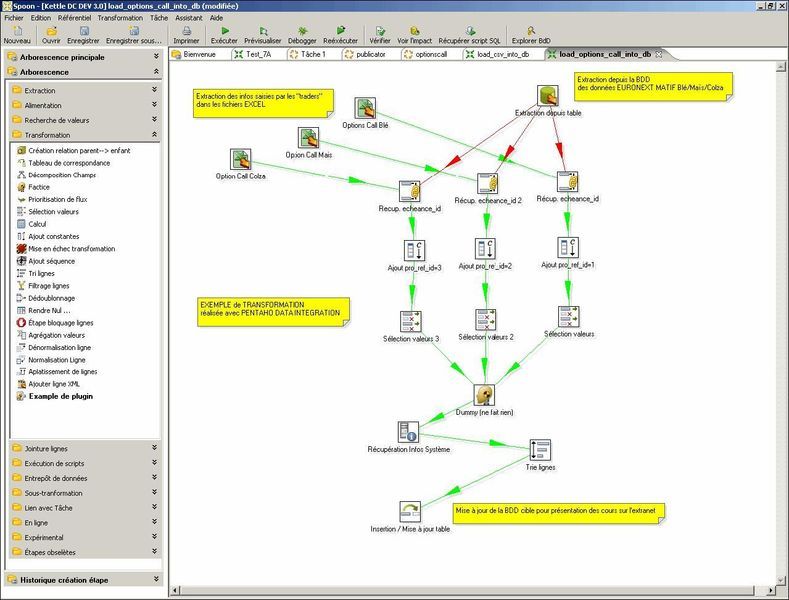
Spoon, l'interface graphique de création des transformations et jobs :
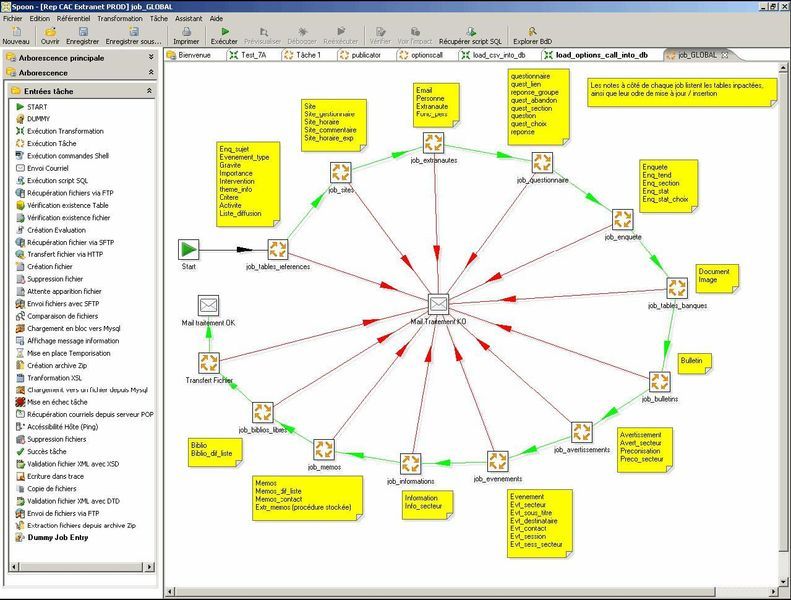
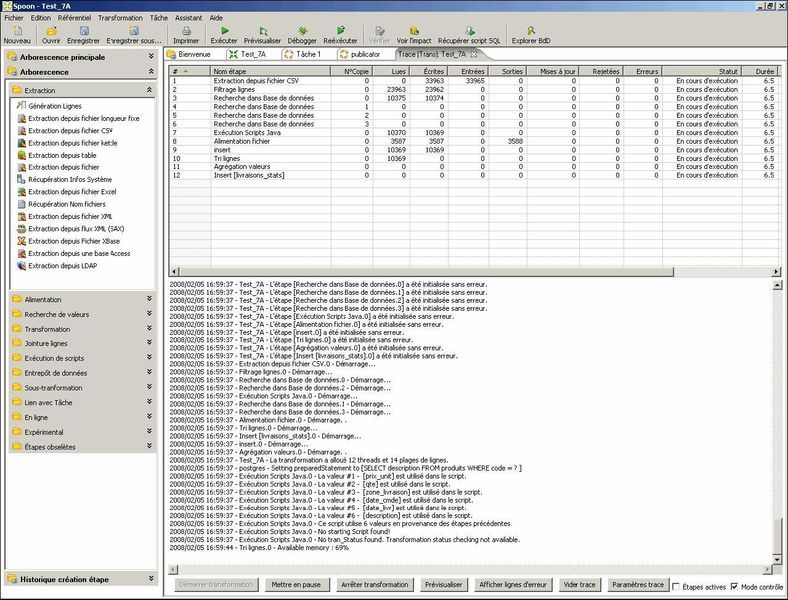
Spoon, le suivi des traitements « real time » :
Briques de traitements de données (liste non exhaustive) :
| Step | Etape | Description |
|---|---|---|
| Extraction depuis EXCEL | |
Extraction de données depuis un ou plusieurs onglets d'un fichier XLS |
| Extraction depuis ACCESS | |
Extraction de données depuis une table d'une base Access |
| Extraction depuis une base de données | |
Extraction de données depuis une table d'un SGBD (Oracle, MySql, Postgres, SQLServer, DB2, AS400, SAP, etc...) : 30 SGBD supportés via JDBC et/ou ODBC |
| Extraction depuis un fichier | |
Extraction de données depuis un fichier CSV ou de type « délimité » |
| Extraction depuis un fichier XML | |
Extraction de données depuis un fichier XML |
| Extraction depuis un annuaire | |
Extraction de données depuis un annuaire de type LDAP |
| Alimentation base de données | |
Insertion ou mise à jour d'une table d'un SGBD (insert/update) |
| Recherche dans base de données | |
Recherche des enregistrements dans une base de données selon une liste de valeurs |
| Recherche dans un flux | |
Recherche des enregistrements dans un flux de données selon une liste de valeurs |
| Normalisation Ligne | |
Normalise des informations |
| Dénormalisation ligne | |
Dénormalisation de lignes |
| Ajout séquence | |
Ajoute une séquence (calculée ou récupérée depuis une base de données) |
| Filtrage de ligne | |
Permet de diriger les flux de données vers 2 cibles différentes selon un ou plusieurs critères |
| Agrégation de données | |
Permet de réaliser des calculs d'agrégation sur un ensemble de lignes (somme, moyenne, min, max, count, etc...) |
| Calculs | |
Permet de créer des données calculées à partir des données traitées |
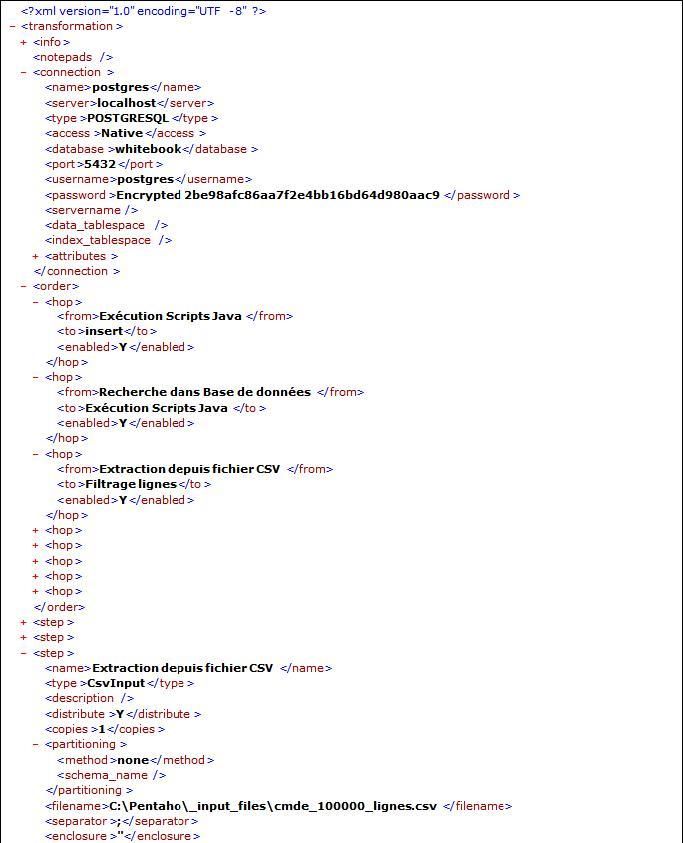
Stockage des traitements au format XML :
Les jobs et transformations sont stockés dans un meta-langage, qui peut être soit stocké au format XML, soit dans une base de données.