III. Pourquoi utiliser un ETL open source ?▲
Le choix le plus difficile dans tout projet décisionnel ou d'intégration/migration de données consiste à déterminer quelle méthode doit être mise en œuvre :
- Faut-il créer du code spécifique (procédures SQL, code Java ou autre) ?
- Faut-il acheter un ETL propriétaire (Informatica, Oracle Warehouse Builder, BO Data Integrator ou autre) ?
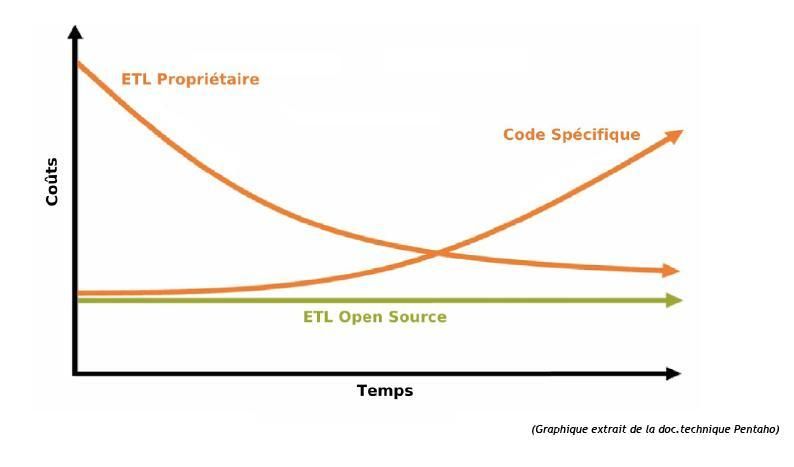
La première solution semble intéressante, car elle permet de rester au plus près des spécificités métier des données à traiter, tout en s'affranchissant des contraintes liées à l'achat et l'utilisation d'un ETL propriétaire. Cependant, cette solution peut s'avérer coûteuse à long terme, tout simplement, car l'évolutivité constante des données métier entraîne une nécessaire adaptation des traitements d'intégration. Celle-ci n'est pas toujours facile à gérer, surtout si les équipes projets évoluent au cours du temps.
La deuxième solution va permettre de mettre en œuvre très rapidement les traitements d'intégration, avec cependant des coûts élevés (achat des licences, formations…) et ceci dès la phase de démarrage du projet.
Il existe désormais une solution alternative : Utiliser un ETL open source.
On bénéficie ainsi des avantages d'un ETL tout en gardant une maîtrise lissée des coûts.
Ces derniers sont en effet réduits aux coûts de formation initiale de l'outil et d'une éventuelle souscription à une hot-line technique. Aucune licence n'est à payer dans ce modèle économique.
C'est donc dans cette 3e approche que se positionnent les ETL « Talend Open Studio » et « Pentaho Data Integration ».
IV. Notre comparatif « Talend Open Studio »/« Pentaho Data Integration »▲
IV-A. Présentation de Talend Open Studio▲
Talend Open Studio est développé par Talend (www.talend.com), une société française dynamique et relativement jeune. La première version de « Talend Open Studio » a vu le jour au 2e semestre 2006, et la version actuelle est la 2.3.
Talend Open Studio est un ETL du type « générateur de code ». Pour chaque traitement d'intégration de données, un code spécifique est généré, ce dernier pouvant être en Java ou en Perl. Les données traitées et les traitements effectués sont donc intimement liés.
Talend Open Studio utilise une interface graphique, le « Job Designer » (basée sur Eclipse RCP) qui permet la création des processus de manipulation de données :
De nombreux types d'étapes sont disponibles pour se connecter aux principaux SGBD (Oracle, DB2, MS SQL Server, PostgreSQL, MySQL…) ainsi que pour traiter tous les types de fichiers plats (CSV, Excel, XML), aussi bien en lecture qu'en écriture.
Talend facilite la construction des requêtes dans les bases de données en détectant le schéma et les relations entre tables.
Un référentiel permet de stocker les métadonnées afin de pouvoir les exploiter dans différents jobs.
Par exemple on peut sauvegarder le type et le format des données d'entrée d'un fichier CSV afin de pouvoir les exploiter ultérieurement.
Une gamme complète de composants
Le Job Designer intègre une « Component Library » : une palette graphique de composants et connecteurs.
Les processus d'intégration sont construits simplement en déposant des composants et connecteurs sur le diagramme, en dessinant leurs connexions et relations, et en modifiant leurs propriétés.
La plupart de ces propriétés peuvent être issues des métadonnées déjà définies.
La Component Library inclut plus de 80 composants et connecteurs, fournissant des fonctions basiques telles que des associations, transformations, agrégations et recherches, des fonctions spécialisées comme le filtrage de données, le multiplexage de données…
Cette librairie supporte tous les principaux SGBDR, formats de fichiers, annuaires LDAP…
La Component Library peut facilement être complétée en utilisant des langages standards tels que Perl, Java ou SQL.
Des traces et statistiques d'exécution en temps réel
La conception très visuelle des « jobs » permet de présenter des statistiques d'exécution en temps réel ou encore de tracer les données transitant ligne à ligne dans les composants de la chaîne de traitement.
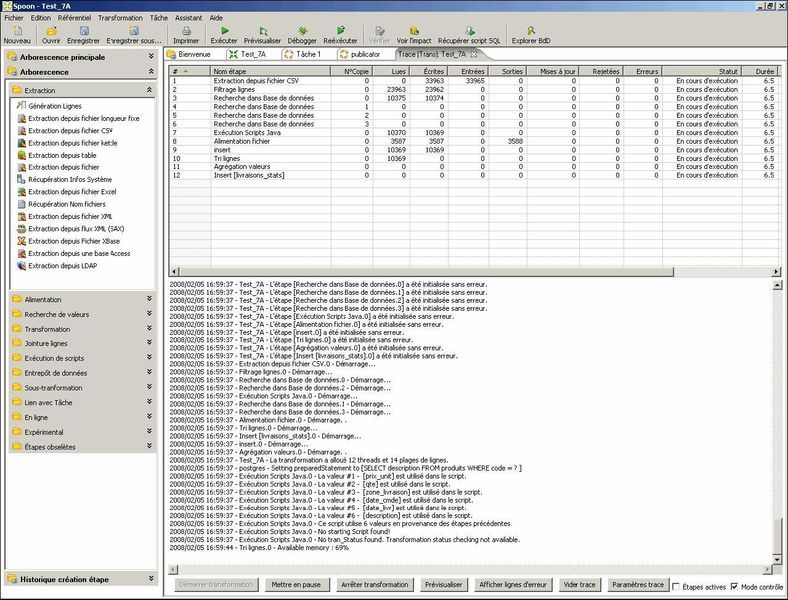
Quand un job d'intégration est lancé via le Job Designer (en mode graphique), il est possible d'afficher les statistiques de traitement en temps réel, montrant le nombre de lignes traitées et rejetées, ainsi que la vitesse d'exécution (lignes par secondes). On peut ainsi repérer immédiatement les goulots d'étranglement.
Il est aussi possible d'activer un mode de traçage, qui affiche pour chaque ligne le comportement adopté et montre le résultat des transformations. Les fonctionnalités de débogage traditionnelles sont évidemment disponibles.
L'enrichissement des traitements par ajout de code spécifique
La totalité du code généré par Talend Open Studio, quel que soit le langage cible, est toujours visible et accessible depuis l'environnement de conception.
On peut bien sûr implémenter des spécificités « métier » propres aux données traitées, ceci en ajoutant de nouvelles « routines ».
Exemple de code généré par Talend Open Studio
Intégration dans les suites décisionnelles open source
Talend est partenaire des éditeurs des suites décisionnelles SpagoBI et JasperIntelligence.
IV-B. Présention de Pentaho Data Integration▲
Pentaho Data Integration est l'ETL de la suite décisionnelle open source Pentaho.
Cet ETL, « Kettle » à l'origine, est le fruit du travail de Matt Casters, un consultant BI qui l'a développé à l'origine pour ses propres besoins au début des années 2000.
Courant 2006, Matt Casters rejoint la société Pentaho, et « Kettle » devient « Pentaho Data Integration ».
Les nouvelles versions s'enchaînent alors à un rythme soutenu. La prochaine version est la 3.0.2 qui doit sortir courant février 2008.
Contrairement à Talend Open Studio, Pentaho Data Integration est un « moteur de transformation » ETL : les données traitées et les traitements à effectuer sont parfaitement séparés. (on parle de « meta-data driven » ETL).
Les traitements sont stockés dans un référentiel (repository) qui peut être soit au format XML (fichiers plats), soit dans une base de données (ce qui permet notamment le partage entre plusieurs designers).
Tout comme Talend Open Studio, de nombreux types de SGBD sont supportés (une trentaine) ainsi que tous les types de fichiers plats (Csv, délimité, Excel, XML).
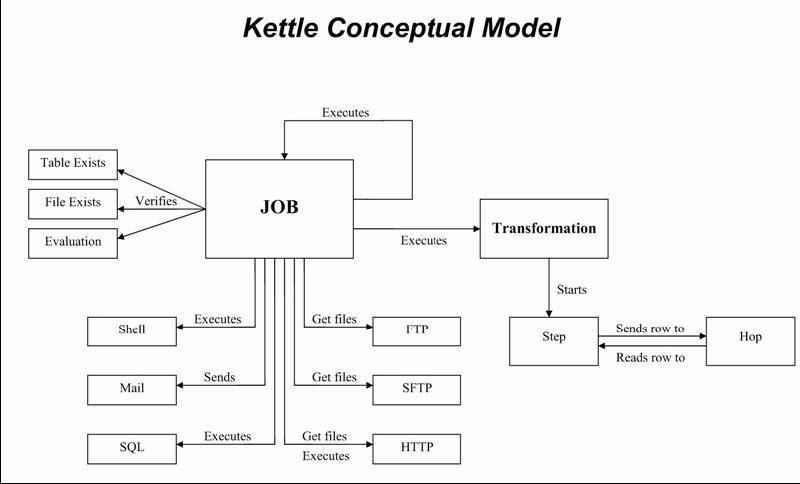
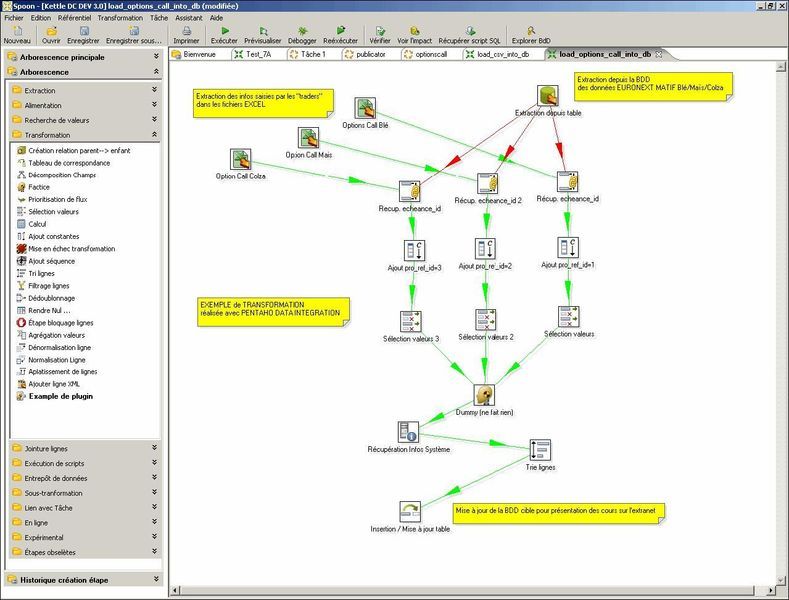
Pentaho Data Integration dipose d'une interface graphique « Spoon » (basée sur SWT), depuis laquelle on peut créer deux types de traitements :
- des transformations : celles-ci constituent les traitements de base d'intégration de données avec toutes les étapes (steps) nécessaires à l'extraction, la transformation, et le chargement des données ;
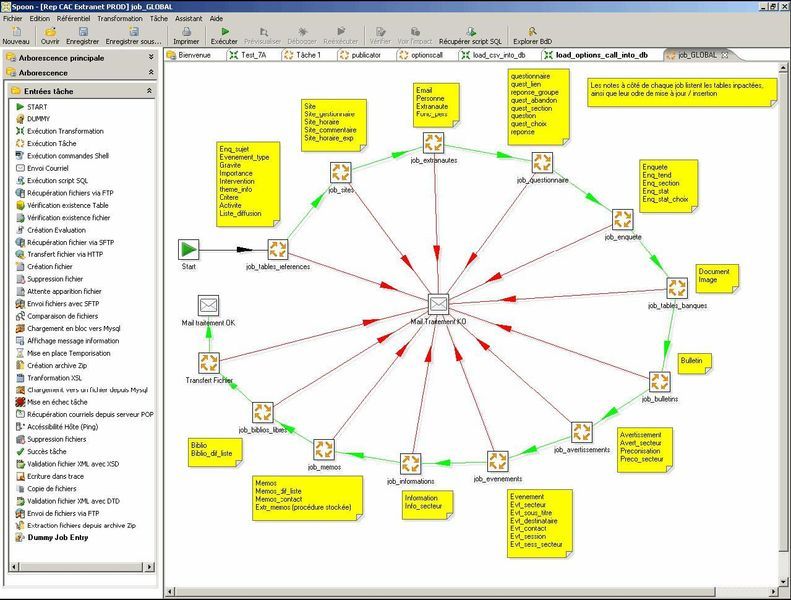
- des tâches (jobs) : ceux-ci permettent le séquencement de plusieurs transformations avec des fonctionnalités plus orientées « EAI » : gestion des erreurs, envoi de mails de notification, transferts FTP/SFTP, exécution de scripts shell ou SQL, etc.
Caractéristiques de Pentaho Data Integration
- Un produit sous licence GNU disponible sur plusieurs systèmes d'exploitation :

- Une suite de 3 composants: L'interface graphique « Spoon », les déclencheurs en mode batch pour les transformations (« Pan ») et les jobs (« Kitchen »).
- Une installation simple (un dossier à décompresser) => un environnement d'exécution JAVA 1.5 suffit.
- La possibilité de prévisualiser les flux de données traitées, et ceci pour une étape donnée.
- La possibilité d'exécuter les traitements sur le poste local, un serveur distant, ou un ensemble de serveurs (exécution en « grappe »; clustering).
- La possibilité de logger les traitements dans une base de données spécifique.
- L'intégration parfaite avec la plate-forme décisionnelle Pentaho. Par exemple, les flux de données en provenance de l'ETL peuvent servir à alimenter des rapports ou des dashboards en temps réel.
Spoon, l'interface graphique de création des transformations et jobs :
Spoon, le suivi des traitements « real time » :
Briques de traitements de données (liste non exhaustive) :
|
Step |
Etape |
Description |
|---|---|---|
|
Extraction depuis EXCEL |
|
Extraction de données depuis un ou plusieurs onglets d'un fichier XLS |
|
Extraction depuis ACCESS |
|
Extraction de données depuis une table d'une base Access |
|
Extraction depuis une base de données |
|
Extraction de données depuis une table d'un SGBD (Oracle, MySql, Postgres, SQLServer, DB2, AS400, SAP, etc.) : 30 SGBD supportés via JDBC et/ou ODBC |
|
Extraction depuis un fichier |
|
Extraction de données depuis un fichier CSV ou de type « délimité » |
|
Extraction depuis un fichier XML |
|
Extraction de données depuis un fichier XML |
|
Extraction depuis un annuaire |
|
Extraction de données depuis un annuaire de type LDAP |
|
Alimentation base de données |
|
Insertion ou mise à jour d'une table d'un SGBD (insert/update) |
|
Recherche dans base de données |
|
Recherche des enregistrements dans une base de données selon une liste de valeurs |
|
Recherche dans un flux |
|
Recherche des enregistrements dans un flux de données selon une liste de valeurs |
|
Normalisation Ligne |
|
Normalise des informations |
|
Dénormalisation ligne |
|
Dénormalisation de lignes |
|
Ajout séquence |
|
Ajoute une séquence (calculée ou récupérée depuis une base de données) |
|
Filtrage de ligne |
|
Permet de diriger les flux de données vers deux cibles différentes selon un ou plusieurs critères |
|
Agrégation de données |
|
Permet de réaliser des calculs d'agrégation sur un ensemble de lignes (somme, moyenne, min, max, count, etc.) |
|
Calculs |
|
Permet de créer des données calculées à partir des données traitées |
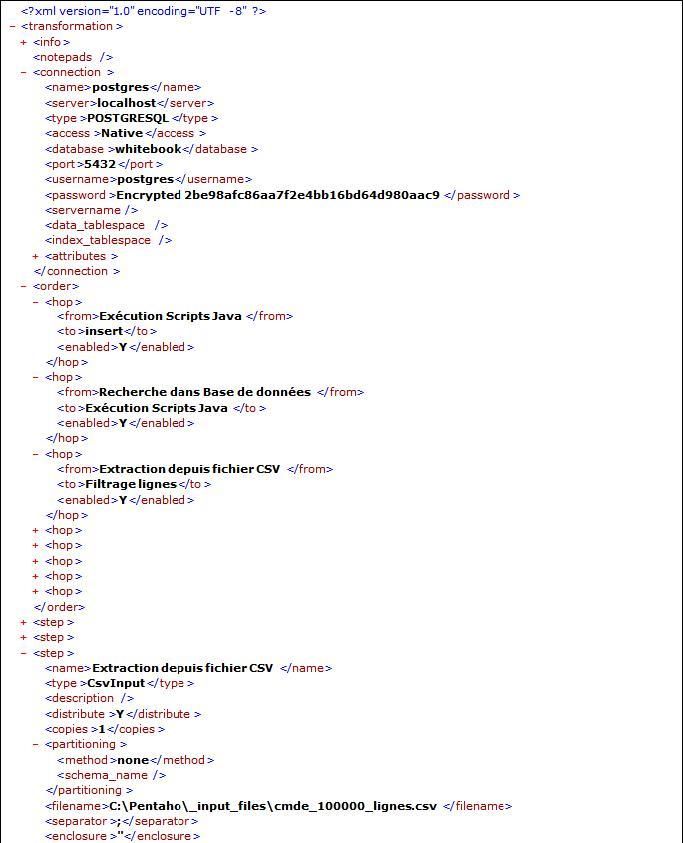
Stockage des traitements au format XML
Les jobs et transformations sont stockés dans un métalangage, qui peut être soit stocké au format XML, soit dans une base de données.
IV-C. Comparatif des fonctionnalités▲
IV-C-1. Accès aux données▲
Accès aux données relationnelles (SGBD)
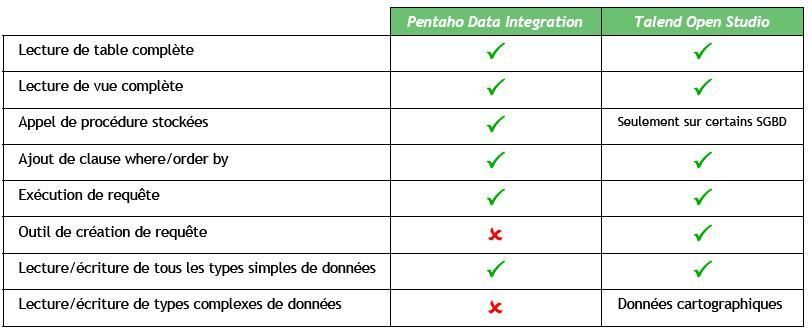
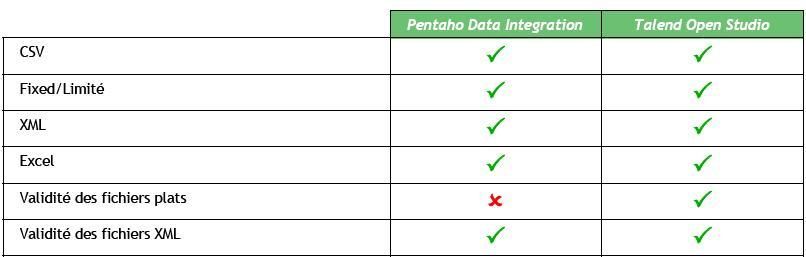
Fichiers plats
Connecteurs applicatifs

Autres

IV-C-2. Déclenchement des processus▲
Déclenchement par message
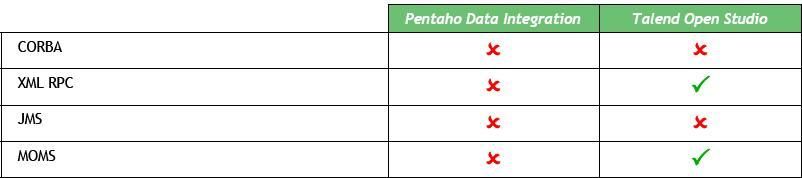
Déclenchement par type de polling

IV-C-3. Traitement des données▲
Transformations et calculs par défaut
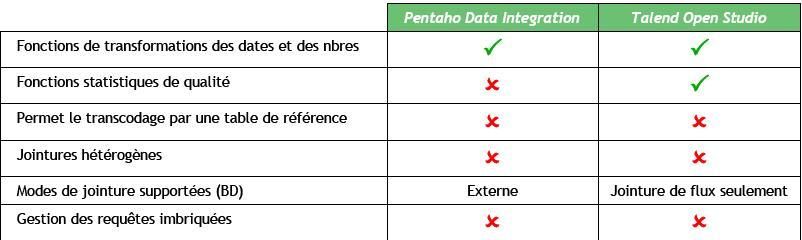
Attention : les étapes marquées « NON » ci-dessus sont seulement pour la prise en charge automatique. Les deux outils fournissent, bien sûr, un mécanisme de requêtage directement en SQL qui permet de faire toutes les jointures et les requêtes imbriquées…
Transformations manuelles

IV-C-4. Traitement des données▲
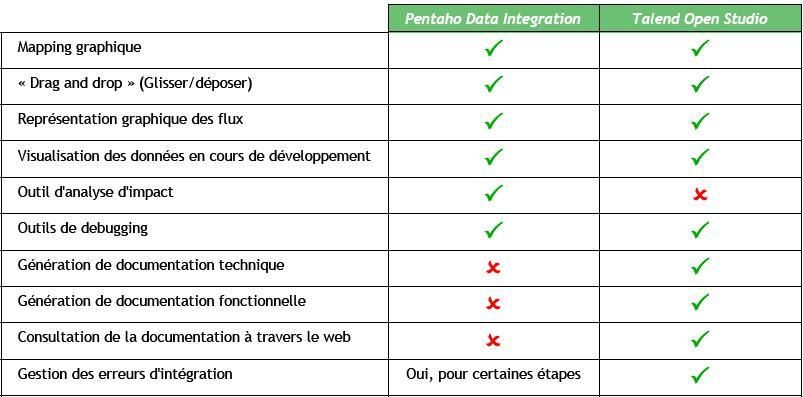
IV-C-5. Développement avancé▲
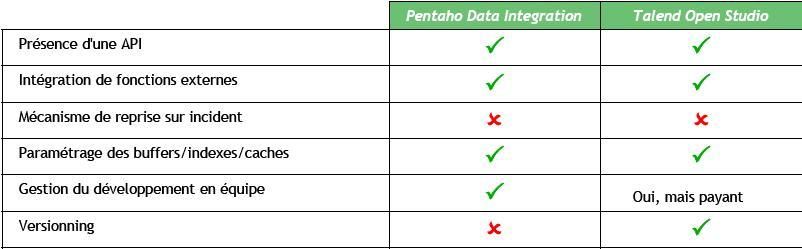
IV-C-6. Déploiement/Mise en production▲

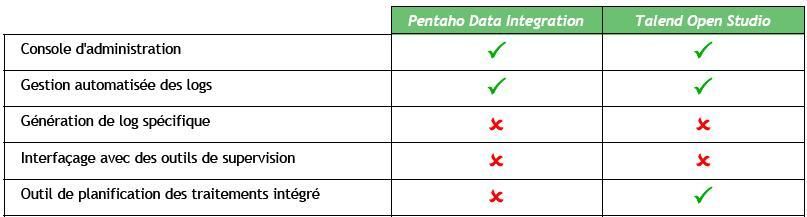
IV-C-7. Administration▲
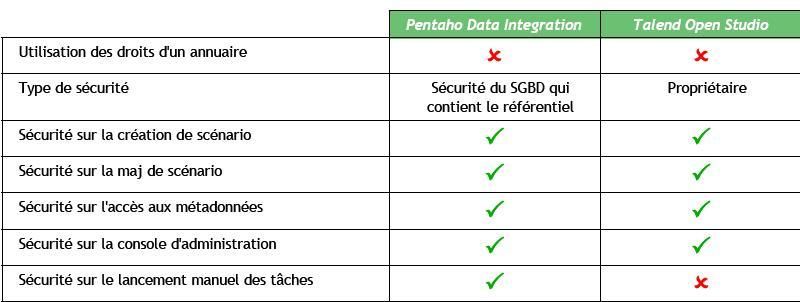
IV-C-8. Gestion de la sécurité▲
IV-D. Comparatif des temps de traitements▲
IV-D-1. Méthodologie de réalisation des tests▲
Les performances des temps de traitements sont un critère important dans le choix d'un ETL.
Les résultats des tests qui sont donnés dans les paragraphes suivants correspondent à des cas simples et ne peuvent en aucun cas préjuger des performances réelles en environnement de production.
Seuls des tests poussés sur des traitements d'intégration réels peuvent permettre de qualifier définitivement l'ETL choisi.
- L'ensemble des tests ont été effectués sur un PC portable Dell
Les caractéristiques techniques sont les suivantes :
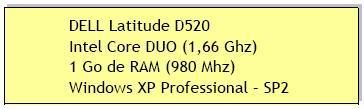
- Les versions utilisées des deux ETL sont les suivantes :
- Pentaho Data Integration v3.0.1 ;
- Talend Open Studio v2.2.3.
- Pour chaque test, les résultats présentés sont issus d'une moyenne de trois essais réalisés dans des conditions identiques.
- Tous les traitements sont lancés en ligne de commande.
Ainsi, aucun essai n'est lancé depuis les interfaces graphiques aussi bien pour Pentaho Data Integration que Talend Open Studio.
- Enfin, les essais sont réalisés uniquement en code généré en Java pour Talend Open Studio, afin que l'on puisse comparer de façon objective ceux obtenus avec Pentaho Data Integration, dont le moteur est écrit en Java.
IV-D-2. Test n°1▲
|
Descriptif |
1. Extraction des données d'un fichier CSV |
|
2. Chargement des données dans un autre fichier CSV |
|
|
- le séparateur « ; » du fichier initial est remplacé par le séparateur « , ». |
|
|
Détails |
Le fichier d'entrée comporte sept champs typés |
|
sequence [integer]; now [datetime]; first [number]; second [string]; third [datetime]; fourth |
|
|
[boolean]; fifth [integer] |
|
|
0000000001;2007/11/0510:44:43.014;12.345;undeuxtroisquatrecinq;0304/12/0500:00:00.000;Y;12345 |
|
|
0000000002;2007/11/0510:44:43.029;12.345;undeuxtroisquatrecinq;0304/12/0500:00:00.000;Y;12345 |
|
|
0000000003;2007/11/0510:44:43.029;12.345;undeuxtroisquatrecinq;0304/12/0500:00:00.000;Y;12345 |
|
|
0000000004;2007/11/0510:44:43.029;12.345;undeuxtroisquatrecinq;0304/12/0500:00:00.000;Y;12345 |
|
|
0000000005;2007/11/0510:44:43.029;12.345;undeuxtroisquatrecinq;0304/12/0500:00:00.000;Y;12345 |
|
|
0000000006;2007/11/0510:44:43.029;12.345;undeuxtroisquatrecinq;0304/12/0500:00:00.000;Y;12345 |
|
|
0000000007;2007/11/0510:44:43.029;12.345;undeuxtroisquatrecinq;0304/12/0500:00:00.000;Y;12345 |
|
|
0000000008;2007/11/0510:44:43.029;12.345;undeuxtroisquatrecinq;0304/12/0500:00:00.000;Y;12345 |
|
|
0000000009;2007/11/0510:44:43.029;12.345;undeuxtroisquatrecinq;0304/12/0500:00:00.000;Y;12345 |
|
|
0000000010;2007/11/0510:44:43.029;12.345;undeuxtroisquatrecinq;0304/12/0500:00:00.000;Y;12345 |
|
|
etc. |
|
|
Modélisation dans Pentaho Data Integration (PDI) |
|
|
Modélisation dans Talend Open Studio |
|
|
Résultats du Test |
|
|
(Temps de traitement exprimés en sec.) |


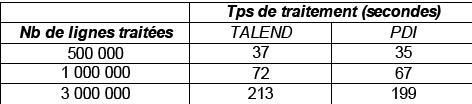
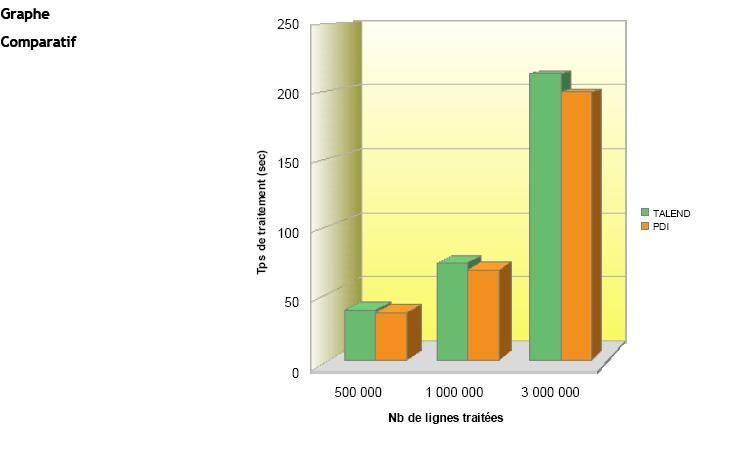
IV-D-3. Test n°2▲
|
Descriptif |
1. Extraction des données d'un fichier CSV |
|
2. Chargement des données dans un fichier XML |
|
|
Détails |
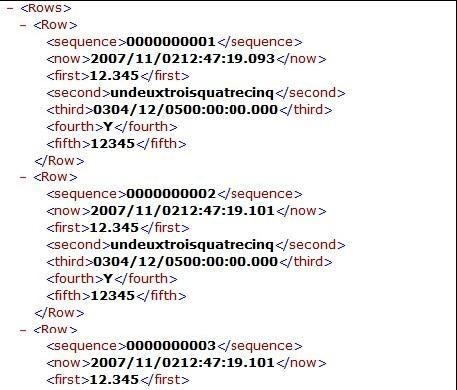
Le fichier d'entrée comporte 7 champs typés (même fichier que Test1) |
|
Le fichier de sortie est un fichier XML dont la structure est la suivante : |
|
|
|
|
|
Modélisation dans Pentaho Data Integration (PDI) |
|
|
Modélisation dans Talend Open Studio |
|
|
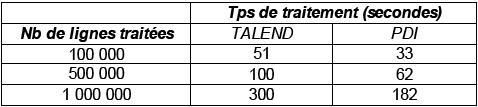
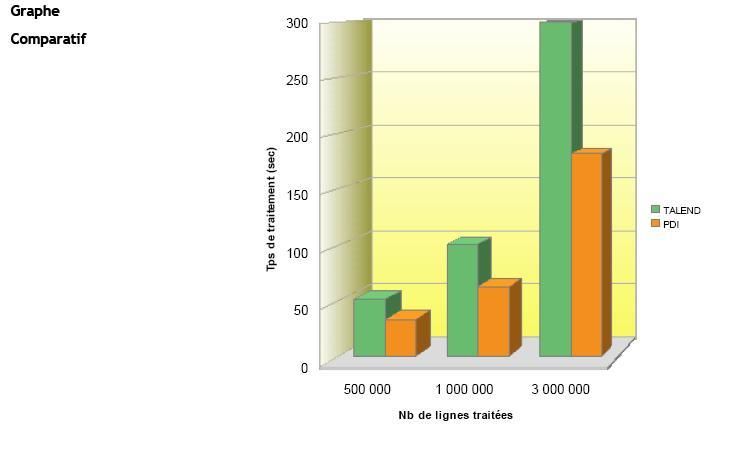
Résultats du Test |
|
|
(Temps de traitement exprimés en sec.) |
|

IV-D-4. Test n°3▲
|
Descriptif |
1. Extraction des données d'un fichier CSV |
|
2. Chargement des données dans une table Postgresql |
|
|
Détails |
Le fichier d'entrée comporte 7 champs typés (même fichier que Test 1 et 2) |
|
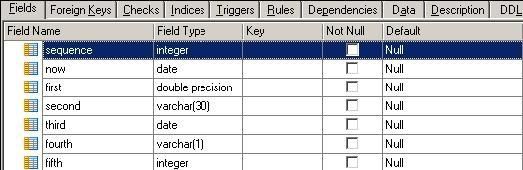
La table Postgresql chargée comporte les champs suivants : |
|
|
|
|
|
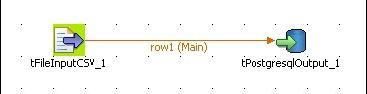
Modélisation dans Pentaho Data Integration (PDI) |
|
|
Modélisation dans Talend Open Studio |
|
|
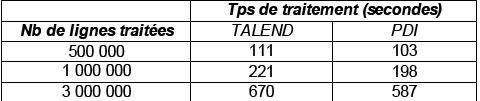
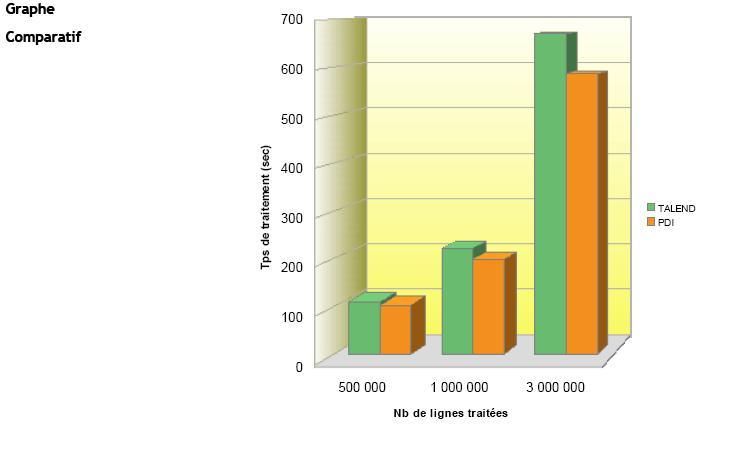
Résultats du Test |
|
|
(Temps de traitement exprimés en sec.) |

IV-D-5. Test n°4▲
|
Descriptif |
1. Extraction des données d' un fichier « commandes » (format) CSV |
|
2. Chargement des données dans une table [livraisons] avec calcul du délai de livraison et du montant global de chaque commande. Récupération du nom littéral du produit via un « lookup » sur la table [produits] à partir de son code. |
|
|
Détails |
Le fichier « commandes.csv » possède la structure suivante. Il existe 26 zones de livraisons (A, B, C, D, … , X, Y, Z) : |
|
|
|
|
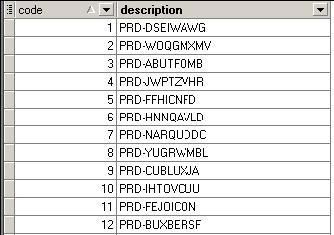
La table [produits] possède la structure suivante. Cette table (générée aléatoirement pour les tests) contient le code et la description de 100 000 produits : |
|
|
|
|
|
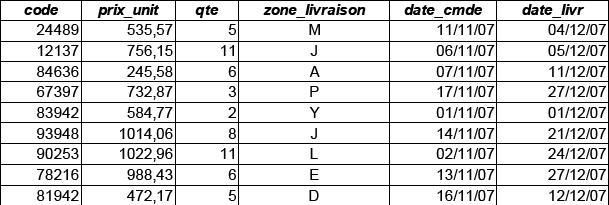
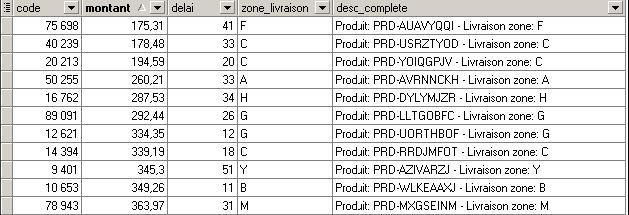
La table cible [livraisons] doit contenir les données ci-dessous après traitement : |
|
|
[livraisons].[montant]= {prix_unit} x {qte} |
|
|
[livraisons].[delai]= {date_livr} - {date-cmde} |
|
|
[livraisons].[desc_complete]= Texte comprenant {description produit} et {zone_livraison} |
|
|
|
|
|
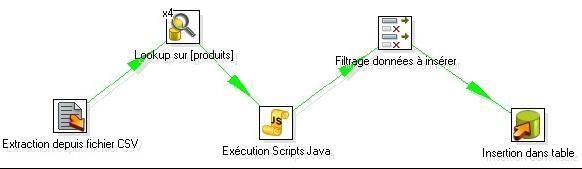
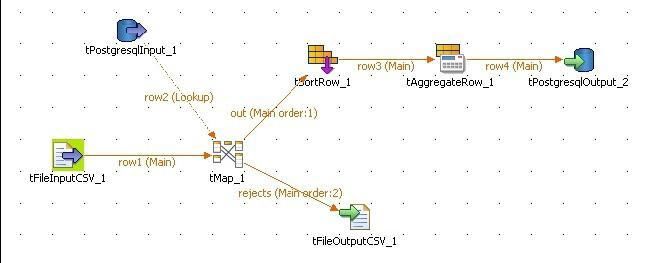
Modélisation dans Pentaho Data Integration (PDI) |
|
|
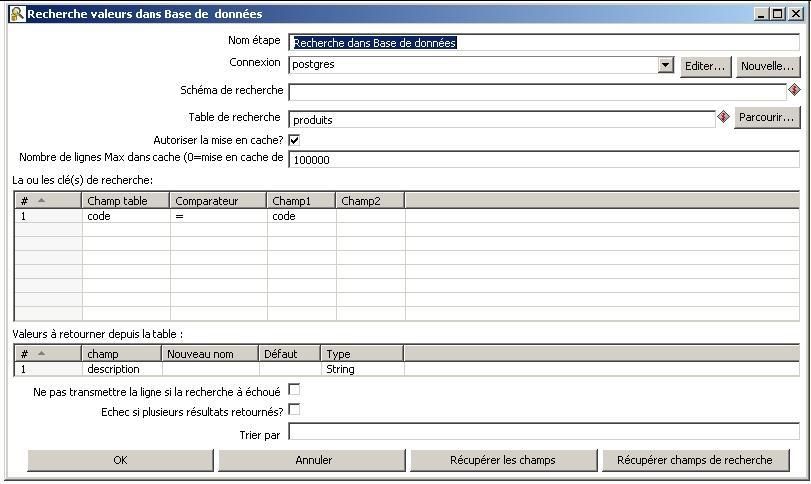
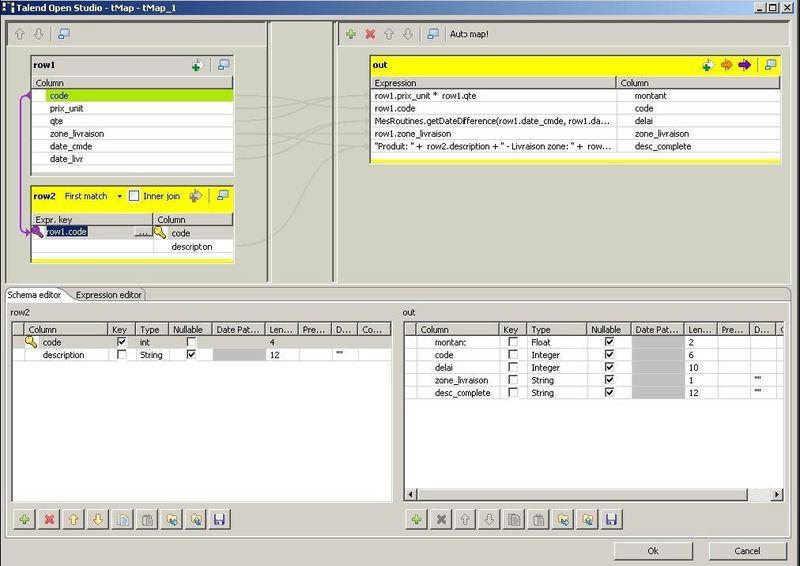
Le lookup sur la table [produits] permet de ramener la description du produit à partir du code produit présent dans le fichier d'entrée : |
|
|
|
|
|
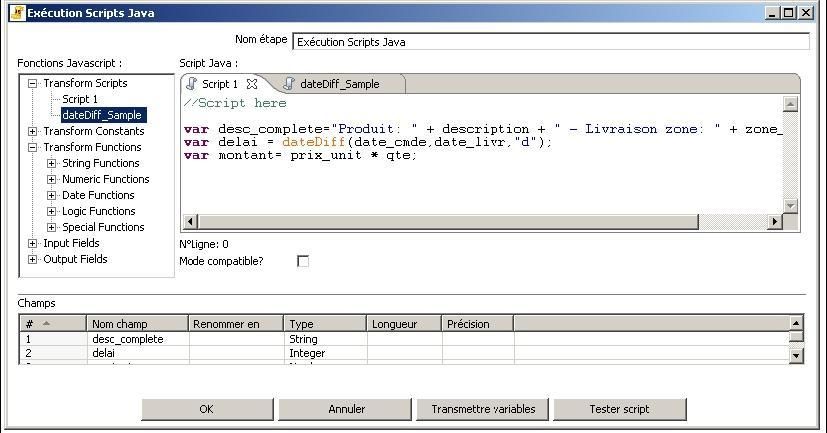
L'étape « JavaScript » permet la réalisation des calculs : |
|
|
|
|
|
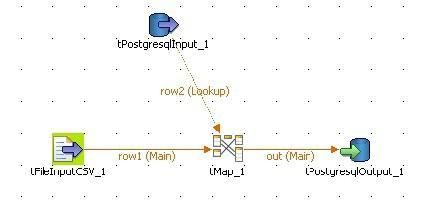
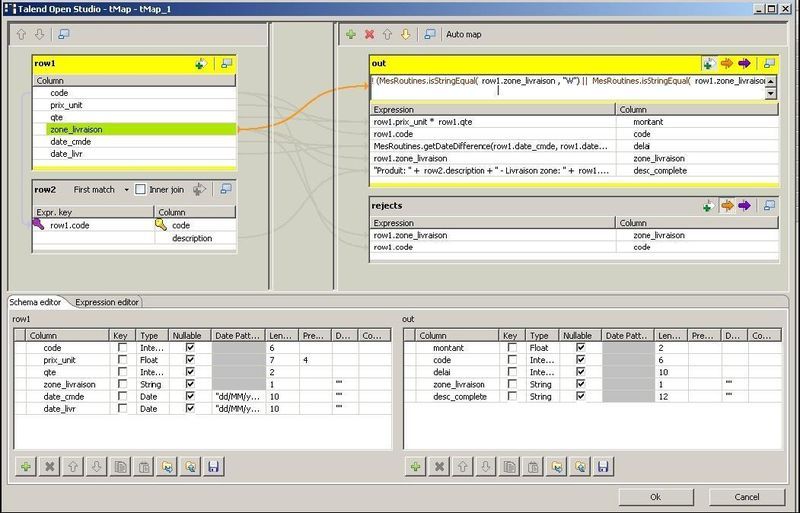
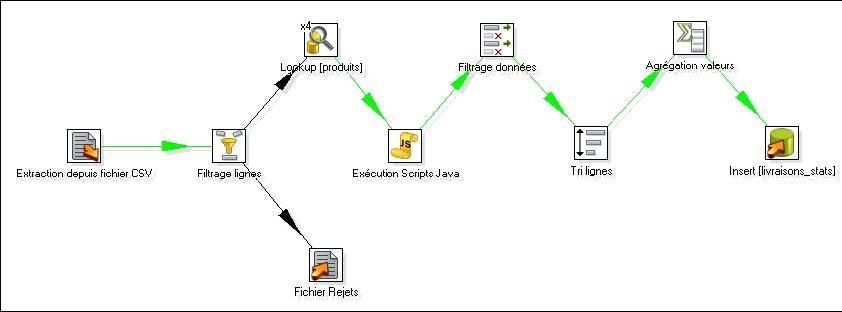
Modélisation dans Talend Open Studio |
|
|
Le composant tMap, permet à la fois de réaliser le lookup sur la table [produits] et la réalisation des différents calculs : |
|
|
|
|
|
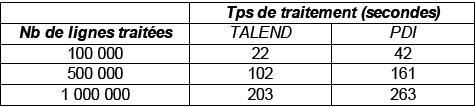
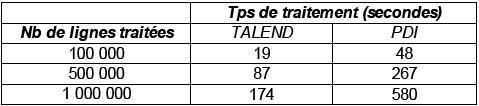
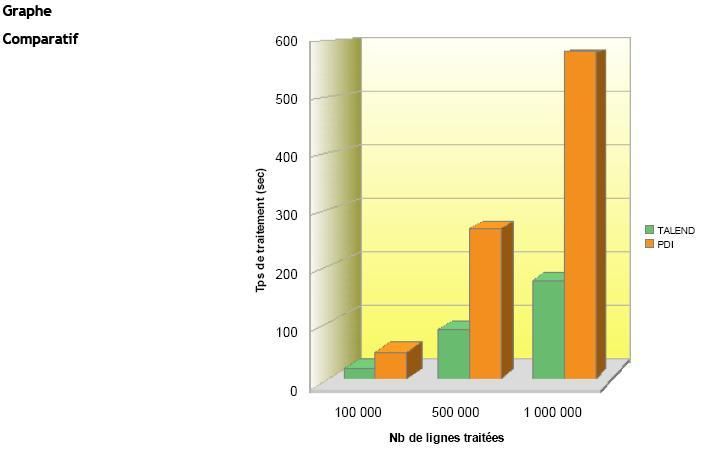
Résultats du Test |
|
|
(Temps de traitement exprimés en sec.) |
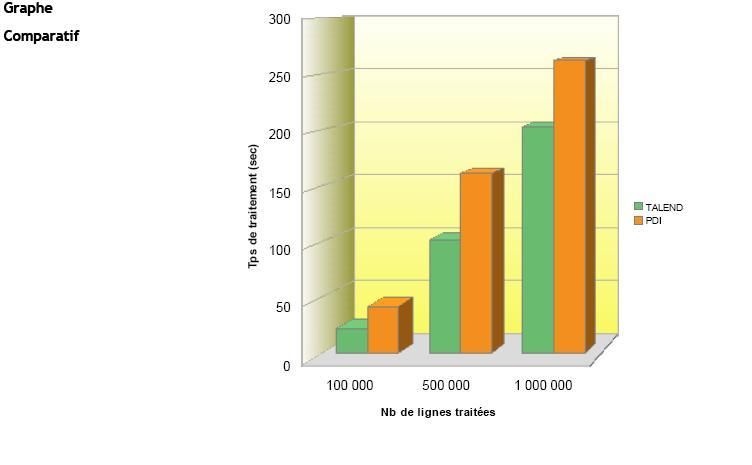
IV-D-6. Test n°5▲
|
Descriptif |
Test identique au Test 4, sauf qu'on isole au début du traitement toutes les données provenant venant des zones de livraisons codées W, X, Y et Z |
|
Ces lignes isolées sont exportées dans un fichier CSV pour traitement ultérieur. |
|
|
Détails |
Le fichier CSV des lignes rejetées contient ainsi le code produit et la zone de livraison rejetée associée (W, X, Y ou Z) |
|
Modélisation dans Pentaho Data Integration (PDI) |
|
|
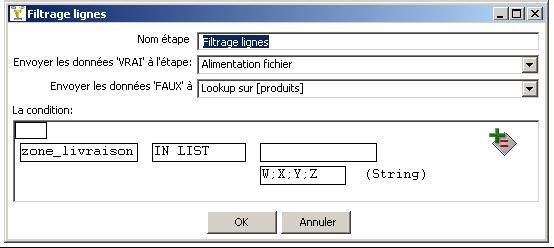
Le filtrage des lignes s'effectue de la façon suivante : |
|
|
|
|
|
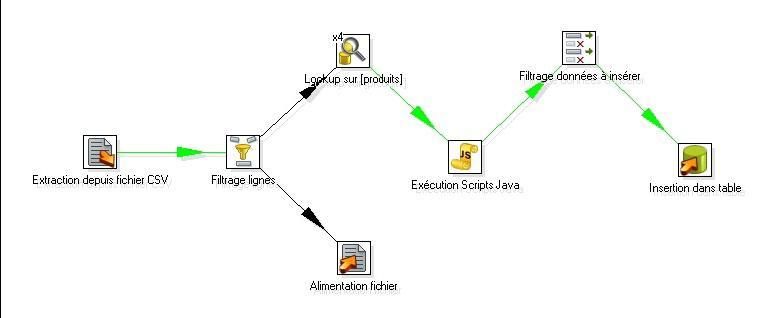
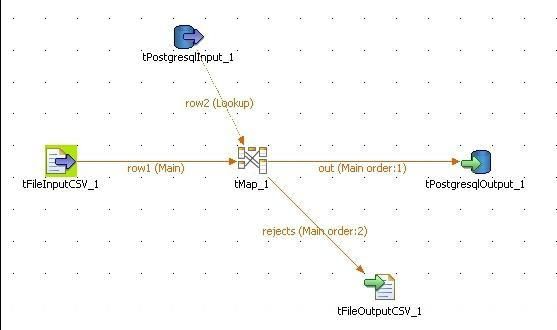
Modélisation dans Talend Open Studio |
|
|
Comme dans le test 4, c'est le composant tMap qui permet d'isoler les lignes à rejeter : |
|
|
|
|
|
Résultats du Test |
|
|
(Temps de traitement exprimés en sec.) |
IV-D-7. Test n°6▲
|
Descriptif |
Test identique au Test 5, avec alimentation d'une table d'agrégation [livraisons_stats] |
|
Détails |
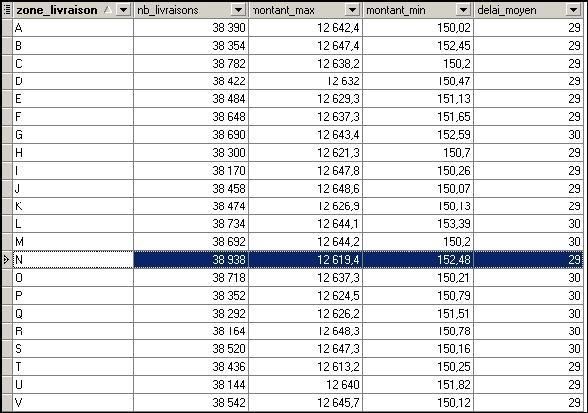
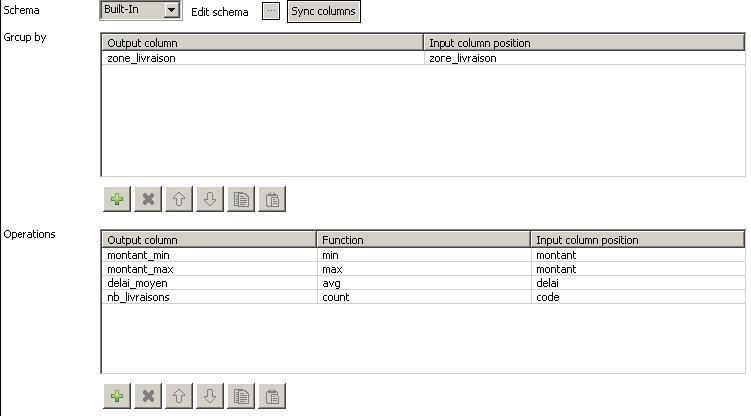
La table d'agrégation [livraisons_stats] doit contenir les données ci-dessous après les traitements suivants. Le groupement de données est effectué pour chaque zone de livraison. |
|
[livraisons_stats].[nb_livraisons]= {nb total de livraisons sur la zone} (count) |
|
|
[livraisons_stats].[montant_max]= {montant maxi d'une commande pour la zone} (max) |
|
|
[livraisons_stats].[montant_min]= {montant mini d'une commande pour la zone} (min) |
|
|
[livraisons_stats].[delai_moyen]= {delai moyen de livraison pour la zone} (avg) |
|
|
|
|
|
Modélisation dans Pentaho Data Integration (PDI) |
|
|
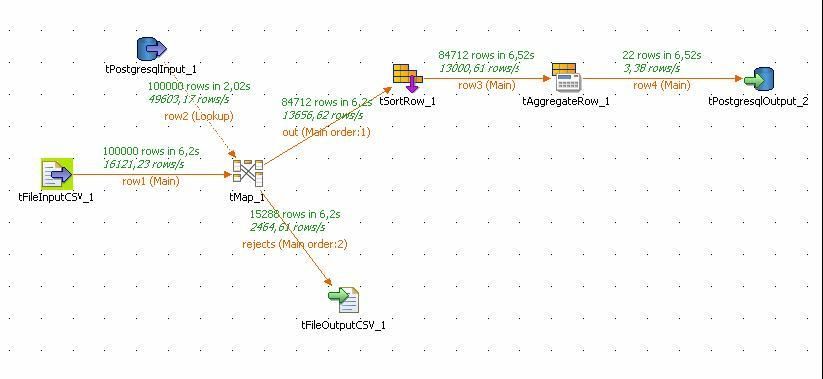
Pour que les calculs d'agrégation soient corrects, le flux de données doit être trié par zone de livraison. Détail de l'étape « Agrégation de valeurs » : |
|
|
|
|
|
Modélisation dans Talend Open Studio |
|
|
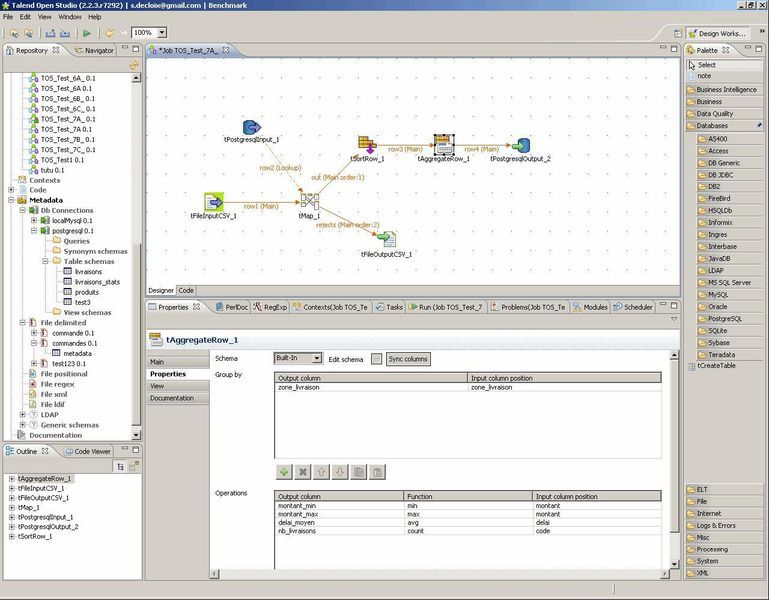
Pour que les calculs d'agrégation soient corrects, le flux de données doit être trié par zone de livraison. Détail de l'étape « tAggregateRow » : |
|
|
|
|
|
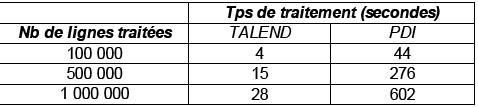
Résultats du Test |
|
|
(Temps de traitement exprimés en sec.) |

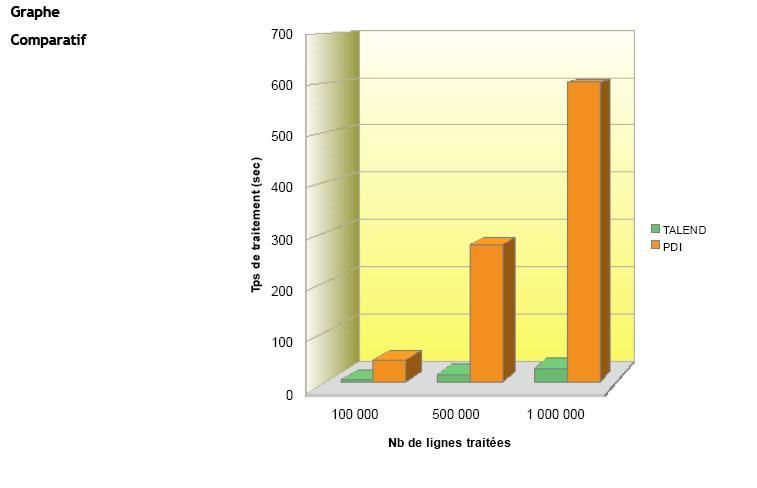
IV-D-8. Test n°7▲
|
Descriptif |
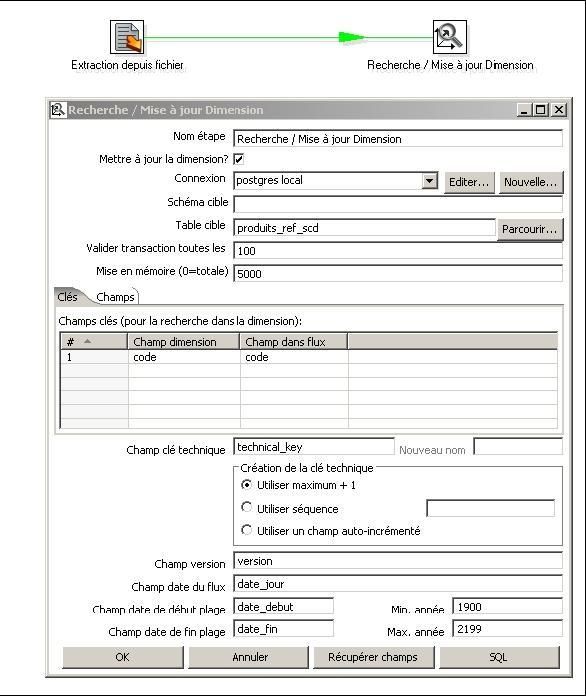
Utilisation d'une étape de traitement « Dimension lente » de type 2 |
|
Pour plus d'infos sur les différents types de « Slow Changing Dimension » consulter la page : |
|
|
Détails |
La table [produits_ref_scd] permet l'historisation des prix d'un catalogue produit. |
|
Extrait de la table avant le traitement : |
|
|
|
|
|
Le fichier traité indique le code et le prix de l'article à la date du traitement : |
|
|
100; 746.48 |
|
|
101; 528.72 |
|
|
Une fois le traitement effectué, la table [produits_ref_scd] stocke l'historique des prix : |
|
|
|
|
|
Pour un code produit donné, dès que le prix est différent de celui présent en base, un nouvel enregistrement est créé avec un nouveau numéro de version. La période de validité est également mise à jour (date_debut, date_fin) |
|
|
Modélisation dans Pentaho Data Integration (PDI) |
|
|
Modélisation dans Talend Open Studio |
|
|
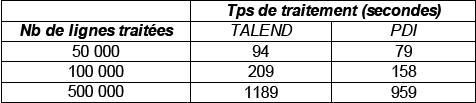
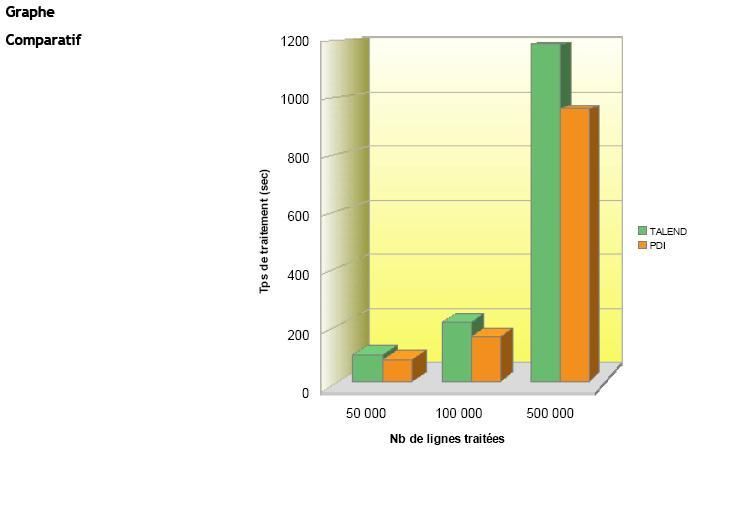
Résultats du Test |
|
|
(Temps de traitement exprimés en sec.) |